This post describes Backbone concepts and programming techniques and (its main purpose) it points you to demonstrations of these within my JavaScript Code Tracker (JSCT) application.
JavaScript Code Tracker: a Backbone demo app
JavaScript Code Tracker (JSCT) is a web application that demonstrates some basics of JavaScript Single Page Applications (SPAs) and Backbone, a JavaScript MV* lib.
Aspects of SPAs demonstrated include:
- browser-based application driven by the client, not the server — single page load
- common JS coding practices such as use of an application namespace and minimal use of global namespace, closures for privacy, use of templates, use of "use strict", etc.
- responsive design to handle browser resize and mobile browsers (incl. orientation change)
- save/restore of application state (very basic here, localStorage is used)
Aspects of Backbone demonstrated include:
- separation of Model and View layers via Backbone classes Model, View, Collection
- loose coupling through Backbone events (including use for simple pub/sub)
- CRUD through Backbone methods create, fetch, save, destroy, etc.
- application navigation/bookmarking through Backbone Router and History classes
This post assumes you're familiar with JavaScript and jQuery. You should also know the basics of JavaScript applications development — while you may not have created a Single Page Application you should at least know what a SPA is and the basics of developing one.
As for your Backbone knowledge, this post assumes you're noobish but not a total noob — while this does summarize core concepts mostly it focuses on providing JSCT examples of these concepts so you'll get more out of this if you've already read up on Backbone basics.
JavaScript Code Tracker: a Backbone demo app
Data: models and collections, data handling, localStorage
Using Model events to keep views sync'd with their data
UI: views, DOM manipulation, garbage collection
The view's DOM element and el property
Rendering and working with views off-DOM
Navigation: routing, use of history, bookmarking
Connecting URLs and application state
Loose Coupling: events and pub/sub
Custom events including Publish/Subscribe
JSCT application controller, application model, application state
Application model and application persistence
Overview
JSCT is a simple web application to help programmers keep track of coding tips and traps, good sample code, demo apps, etc. At least that's its apparent purpose. Actually it's just a vehicle for exploring Backbone and demonstrating its features. In that regard it's similar to Addy Osmani's TodoMVC application for Backbone, which lets you see a simple Backbone application in action while also providing commented source code along with online content that describes the application architecture. In fact JSCT uses the TodoMVC application as its starting point, extending it and in some places restructuring it to demo more Backbone features.
 |
If you're a total Backbone noob you should start with the Backbone version of TodoMVC, it's simpler than JSCT so is better for learning the fundamentals. Moreover, Addy Osmani has a long description of TodoMVC in his book "Developing Backbone.js Applications" (available online or purchase from O'Reilly). |
Like the TodoMVC Backbone application, JSCT lets you do CRUD on a simple dataset. In TodoMVC you work with a list of tasks while in JSCT it's a list of programming resources. Other differences: JSCT uses more views (and more nested views), makes greater use of Backbone routing, uses an extend of the Backbone events class for a pub/sub events aggregator. It also throws in other commonly used web application features like save/restore of application state, some responsive design, crude use of state machine, and more. You might think of Osmani's TodoMVC application as a useful first step into Backbone while JSCT is a (hopefully also useful) second step.
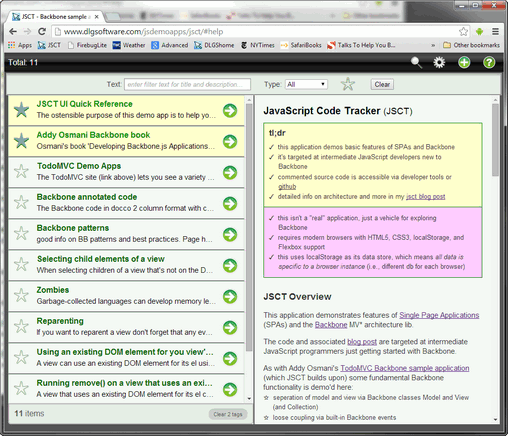
JSCT screencap — dualPane layout (click to run)
Caveats
Because this is a demo app for noobs it favors clarity over performance and skips some best practices when they get in the way of code accessibility/readability. That means JSCT's code isn't minified or run through a code optimizer — I don't want to optimize away the code's many comments and descriptive variable names. I also don't concatenate my .js files — having files kept separate means the application structure is easier to see in developer tools like Chrome's DevTools. This all has a performance cost, of course, and isn't something you'd want to do in a production application.
This demo app assumes you're using a modern browser — it doesn't polyfill missing features into older browsers. It also doesn't address some browser-specific quirks (particularly for the horrific Android stock browser). For a list of unaddressed quirks and small bugs see the Known Issues section below.
Bottom line here: this isn't a model application, and it's certainly not a production-quality application, it's just a simple demo app for exploring SPAs and Backbone.
 |
Like many sample applications JSCT makes trade-offs for clarity and uses implementations that may not scale. When looking at the code keep in mind that JSCT isn't a model application, it's intended only to demonstrate and explore SPA and Backbone basics. |
One last caveat: I'm no Backbone guru, and much of this was written as I was diving into Backbone myself, so I apologize in advance for any errors or omissions (feedback is very welcome).
JSCT code
JSCT's JavaScript is spread across multiple .js files which are organized by role. Because these .js files are loaded via individual <script> tags (i.e., they're not concatenated) you can see JSCT's files structure in developer tools such as Chrome's DevTools (screengrab below).
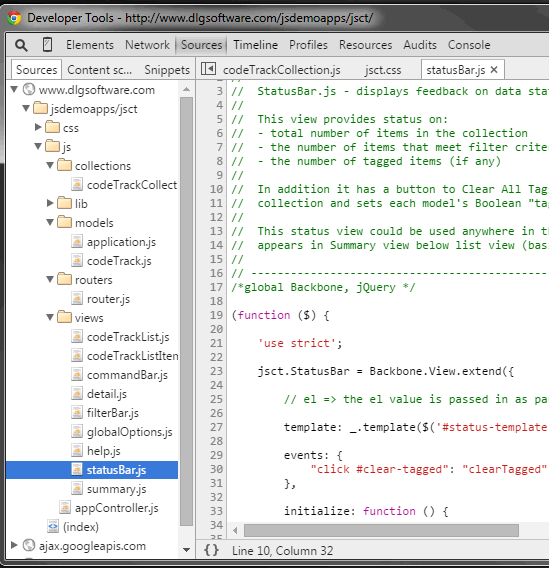
Chrome DevTools Sources pane showing files organization
JSCT's JavaScript files are organized by role under a js directory, for example Backbone models are stored in js/models, Backbone views in js/views, etc.
You might notice there's no /templates folder. That's because all templates used by this demo app are defined within index.html. That was done to simplify things a bit, but note that it's not a good practice, it's generally better to have templates as separate files.
JSCT code is accessible through developer tools like Chrome DevTools and Firebug or on github. This code is filled with comments (annoyingly overcommented at times, but remember this is targeted at noobs) and uses long and hopefully descriptive variable names.
As you read the code keep in mind that sometimes a task is performed several ways in order to demo different approaches to completing that task. An example of this is the creation of child elements in views: most JSCT views take the normal route of creating their UI through markup that comes from templates, but some create their children "manually" by creating and manipulating the DOM nodes via JavaScript/jQuery, and two have markup that defines their UI directly embedded in the application's index.html. Where alternative approaches are explored they're usually described and compared within this doc or in the code's comments.
| |
JSCT code is heavily commented. Don't rely solely on what's in this post, there's often additional information on a topic available in the code's comments. |
Details on the roles and locations of individual files are provided in context below (e.g., descriptions of model and collection files appear in the Models and Collections section).
JSCT developer diagnostics
JSCT has an option for writing info on internal processes to the JavaScript console. When enabled you'll see messages in the console that tell you what's happening, when it's happening, and where it's happening. This should make it easier to understand how the application (and Backbone) works. The screen below shows sample output from application initialization.
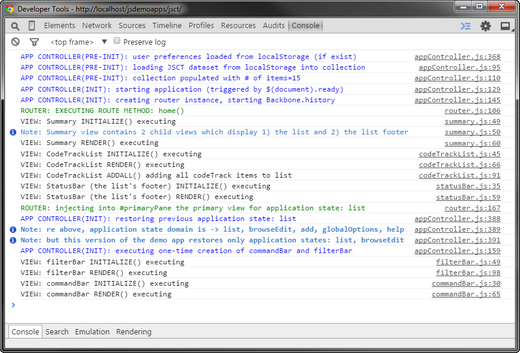
Sample of JSCT diagnostics in JS console
Notes on this diagnostics option:
- you can enable the developer diagnostics in the global options view or from the console (see next bullet)
- the display of these diagnostic messages is controlled by Boolean jsct.showDiags. This means you can enable/disable diagnostics by assigning jsct.showDiags true/false in the console.
- your preference for showing diagnostics is saved/restored across sessions (so if you enable it and then reload you can see info on the pre-init and init processes)
- most jsct.showDiags conditionals use a single line for tighter, more readable code, but this is NOT a best practice
- this option doesn't use a centralized logger function, ensuring that each message shows the module and line number it was generated from. In most consoles this makes it easy to jump to that location (useful when you want to drill down into a process)
- for readability some console lines are colored, though you won't see this in IE (with IE11 MSFT has gotten better at adopting de jure and de facto standards but it's still got a ways to go)
| |
To get a handle on what JSCT is doing internally go to the global options view and enable its "Developer diagnostics" option or in the console just set jsct.showDiags=true. |
Architecture
Overview
JSCT is a browser-based application that's driven by client-side JavaScript, not by a web server. More specifically, it's a Single Page Application (SPA), which means that it has a single initial page load. Once loaded it needs no more loads to respond to user input — JavaScript (jQuery, Backbone, Underscore, etc.) is used on the client to store/manage data locally and to create/manage the presentation of this data. By avoiding page loads and by using locally generated views these client-driven SPAs can deliver a smoother UI that's more like a desktop application than traditional server-driven web applications.
Like most SPAs this demo app employs a MV* architecture — that is, it separates data and data handling code (Model) from data presentation code (View). Among other benefits this simplifies keeping views in sync with the data they're presenting. A discussion of MVC and MV* is beyond the scope of this post but the bullets below contain key points on MV* as it pertains to Backbone applications.
Some general notes on the role and usage of Models:
- the Model is your logical data layer, holding domain data and the logic for managing this data
- this Model layer is generally composed of many individual models — for example, an application for a retail business might make use of a store model, an inventory model, an employee model, a manager model that extends the employee model, etc.
- in JavaScript applications the Model is client-side data stored in JavaScript objects, arrays, collections. The Model's processing includes things like calls to fetch data from the server, to parse the results into client-side data structures, to fire events when this data is changed, to validate user-entered data, to send changed values back to the server for commit to the backend db, etc.
- in JavaScript applications the Model holds your application's definitive copy of client-side data. This data may be displayed multiple places in your UI but the values displayed in your DOM elements reflect what's stored in the Model
- in JavaScript applications the client-side Model isn't some clone of the backend data. Instead, this Model is usually a subset of the remote master data, including only the data needed for fast response to user requests (mainly through client-side views generation, which avoids the latency of server requests).
- Backbone's Model class provides features that simplify creating client-side MV* applications. For example, it includes property setters that fire change events whenever a property is modified. These change events can be consumed by views that need to stay in sync with the data they're presenting (i.e., views can listen for change events and refresh themselves whenever the data they're presenting changes)
- to keep things loosely coupled models do not directly communicate with views (i.e., they don't have a reference to them, and thus a dependency). Rather, they communicate changes in their data only indirectly via events
- Backbone's Model class has methods that facilitate CRUD — methods like fetch, save, destroy, sync, etc. This is a major benefit of Backbone and these methods make working with RESTful servers dead simple. While Backbone assumes a REST backend you can override the default behavior to support other datastore APIs (for example, instead of using a RESTful server to store data remotely JSCT uses the Backbone-localStorage adapter to store its data on the client)
- models are often aggregated into list structures. For collecting models into lists Backbone supplies its Collection class, which (like the Model class) fires many events — for example, it fires add and remove events whenever models are added or removed from the collection.
Some notes on Views:
- the View is your logical presentation layer — basically it creates and controls what the user sees on the screen. In MV* the View often includes code that updates the UI and code that responds to user input (a difference from MVC where this is handled by a Controller).
- the View layer is composed of many individual views, or portions of UI — for example, an employee pay history view, an employee address view, a manager direct-reports view, etc.
- in Backbone your individual views can have whatever scope you need — that is, they can be a small piece of UI (e.g., a single button) or a view can be a more complex grouping of DOM elements working together (e.g., a form-like grouping of labels, input fields, and buttons combined into a searchBar view)
- in Backbone it's common to have views composed of other views (child views, nested views)
- JavaScript applications (and thus Backbone applications) display data through DOM elements, usually creating these elements in HTML markup, and usually this markup comes from templates. Templates contain bits of HTML into which data values are substituted at runtime. The result is dynamically generated markup tailored to the data you're presenting.
- in MV* views get their data from the Model layer. Usually the data they display comes from a single model (e.g., your employee view might get its data from an employee model).
- views listen for model events, responding to these events as appropriate (e.g., re-rendering on data change events, or destroying themselves when their model fires a destroy event)
- Backbone views have features that simplify view management. For example, they make it easy to set event listeners on DOM events fired by child elements and on model data. They also have features that simplify clearing event listeners when the view is destroyed (critical for avoiding memory leaks)
- in Backbone applications the classic Controller functionality (the "C" of MVC) isn't clearly defined. Backbone's View class has aspects of both View and Controller. In addition, other classes like the Backbone Router can have some controller-like functionality.
Some notes on the relationship between models and views:
- the Model should know nothing of how its data is used. That is, it should have no dependency on the View layer — individual models don't reference any view directly, nor do they set listeners on any view. This simplifies modification/maintenance and makes the model more reusable for other applications (or for different versions of an application, for example a desktop version versus a small-screen mobile version)
- views (or, in classic MVC, Controllers) do know about the Model layer and can set listeners on models. They can also call model methods. For example, in JSCT you delete a codeTrack by clicking the "Delete" button in Detail view, and that view's click handler responds by calling the destroy() method of the model it's displaying.
While building JavaScript applications doesn't require separate model and view layers you'll likely find that as your applications grow larger and especially when you use the same data in multiple views (or multiple applications) this MV* architecture can save you a lot of headaches. Here's a quote on the relationship between Model and View in Backbone from Phillip Whisenhunt's Smashing post "Backbone.js Tips and Patterns":
"Backbone.js doesn't enforce any real separation of concerns between the data and view layer, except that models are not created with a reference to their view. Because Backbone.js doesn't enforce a separation of concerns, should you? I and many other Backbone.js developers, such as Oz Katz and Dayal, believe the answer is overwhelmingly yes: Models and collections, the data layer, should be entirely agnostic of the views that are bound to them, keeping a clear separation of concerns. If you don't follow a separation of concerns, your code base could quickly turn into spaghetti code, and no one likes spaghetti code."
Data: models and collections, data handling, localStorage
Remember, this post assumes you've read up on Backbone core concepts such as the role of its models, defining model attributes, and setting attribute values. The remaining sections of this post mostly provide a review of core concepts and then point you to examples in JSCT.
Backbone models
As noted above, JavaScript applications often employ a MV* architecture. Backbone assists you with this MV separation of concerns through its Model class. The Model class provides a JavaScript object that holds data like any other JavaScript object but has Backbone benefits built-in — for example, Backbone models fire achange event whenever their data is modified. Backbone's own definition of models is so clear and concise I'll just quote it here:
"Models are the heart of any JavaScript application, containing the interactive data as well as a large part of the logic surrounding it: conversions, validations, computed properties, and access control. You extend Backbone.Model with your domain-specific methods, and Model provides a basic set of functionality for managing changes."
You create models for your application by extending Backbone's Model class, adding in the attributes and behavior required for your data. JSCT defines 2 models. Here's a summary (for more details see their code comments):
- CodeTrack (js/models/codetrack.js) — holds domain data. In JSCT this is information on coding tips and traps, URLs to demos, etc. Model properties include title, description, URL, etc. JSCT has multiple CodeTrack model instances aggregated into a CodeTrackCollection instance (more on collections below).
- Application (js/models/application.js) — holds application state. Contains a property currentState which reflects the active state (i.e., whether user is currently browsing the data, or adding a new item, or viewing the help, or viewing/changing user preferences). In JSCT this model also has properties that reflect whether a data filter is currently active and the filter criteria, whether the application is running in singlePane or dualPane layout, the ID of the last item the user viewed, etc. Most JSCT views respond to changes in values stored in this model. For example, the layout of several views depends on the application model's currentState and currentLayout values. Having application state in a model also simplifies save/restore of JSCT sessions. JSCT has a single Application model instance. Use of this model is covered in the Application Controller section below
Backbone collections
Models are often aggregated into list structures, basically arrays of models. For these list structures Backbone provides its Collection class. As with Backbone's models, its collections fire many useful events. For example, they fire list-oriented events such as add and remove when you add or remove models from the collection.
Collections are also useful for performing operations across models. For example, Backbone Collections include many Underscore functions as methods, and you can use these to perform operations on all models in a collection. A simple example below uses the filter() utility, which applies a test to each item in the collection and returns a new collection containing only items that pass the test.
// Returns new collection with only items that return true (meet criteria)
satisfyFilter: function() {
return collection.filter(function(item){ return item.meetsCriteria; });
},
The code above is derived from JSCT's codeTrackCollection class. The collection's filter() method is run, with filter() iteratively calling a function for each model in the collection (in this case passing to that function a reference to the current model as a parameter named item). The function can evaluate these models however it wants but the function return value must be a Boolean that indicates whether this collection item satisfies the filter criteria (and therefore should be added to the new collection). This example is super-simple, it just returns the meetsCriteria Boolean value that's stored on each CodeTrack model object. While this example is simple keep in mind that the function you provide to filter() can perform any kind of evaluation as long as it returns a Boolean value.
JSCT uses one collection:
- CodeTrackCollection (js/collections/codeTrackCollection.js) . This collection holds codeTrack model instances. It's populated at application pre-init by the application controller (js/appController.js).
Using Model events to keep views sync'd with their data
A Backbone model is ultimately just a JavaScript object. However, you generally don't assign values to a Backbone model using standard object notation, at least not if you want change events. Example (don't do this):
codeTrackModel.title = "some title"; // will *NOT* trigger change event
Instead, to get Backbone's change events you work through the model's setter. Example:
codeTrackModel.set("title","some title"); // setter *will* trigger change event
Backbone model events simplify keeping your views in sync with the data they're presenting because views can listen for model change events and respond to these events by re-rendering, updating themselves with the new data value(s). This is particularly useful when you're presenting a data value in multiple places — now whenever your data value changes all Backbone views displaying that data can catch the model's change event and update themselves, all staying in sync with the data's new value. Here's another quote from Backbone's main page:
"Whenever a UI action causes an attribute of a model to change, the model triggers a "change" event; all the Views that display the model's state can be notified of the change, so that they are able to respond accordingly, re-rendering themselves with the new information. In a finished Backbone app, you don't have to write the glue code that looks into the DOM to find an element with a specific id, and update the HTML manually — when the model changes, the views simply update themselves."
This approach also applies to collections of models — the Backbone Collection class also fires events that views can use to keep themselves in sync. For example, if a view is displaying a list of models stored in a collection it can listen for collection add or remove events to update itself when that collection is modified, adding or removing <li>'s as needed.
Collections also funnel events fired from their models. That is, you can listen for model events through the collection itself. Here's how the Backbone main page puts it: "Any event that is triggered on a model in a collection will also be triggered on the collection directly, for convenience." That's incredibly useful, allowing you to set just one listener on the collection instead of one listener on every individual model (for a JSCT example of this see its FilterBar class).
These Model and Collection events are one of the main benefits of Backbone. They allow you to keep your model decoupled from the application views. That is, they let your model communicate with your views without having references to those views. You could say that the model is not aware of the views and doesn't know or care whether it's data is even being consumed. It simply fires its events when it's supposed to. If any other part of the application is listening for these events, that's fine. If not, well, that's fine, too. The model doesn't care. The key here is that your model has no dependency on your views, it is totally decoupled from the presentation layer.
A JSCT example of views staying in sync with a model is the CodeTrack model's tagged attribute. This attribute holds a Boolean value that indicates whether this item is currently tagged (tagged items are highlighted and can be accessed quickly via a data filter).
The screencap below shows three views that display the tagged attribute value for one or more CodeTrack models (UI used is highlighted in red):
- CodeTrackListItem view: each list item displays the data for one model, with the model's tagged status visible via its star and row highlighting
- Detail view: the "Tagged" field's star shows the tagged status for the selected item
- StatusBar view: the list footer text displays tagged info indirectly: its clear button shows the total number of tagged items in the collection ("Clear N tags")

These views not only display info on the CodeTrack model's tagged attribute, each also allows the user to change those tagged values. Their UI for this:
- CodeTrackListItem view: toggle the Boolean tagged attribute by clicking on the view's star control
- Detail view: toggle the Boolean tagged attribute and commit that change by clicking on the "Tagged:" star and then on the SAVE button
- StatusBar view: to "un-tag" all models click the "Clear N tags" button (sets tagged value for all models to false)
What's important here is how these views respond when the user toggles the tagged state for an item. The view does not simply update its UI to reflect this state change. Instead it just updates the model's tagged attribute, invoking its setter to toggle that Boolean value, and of course use of the setter will trigger a change event. The three views all have a listener for this change event and whenever it fires they respond by updating their UI to reflect the new value. So, change the value in the model and, voila, all three views update, keeping everything in sync.
BTW, the benefit here isn't just in the model's events, more fundamentally it lies in the fact that your model serves as a client-side master copy of this data. That is, values in the model are always the "correct" version of the data on the client. Having a definitive local datastore simplifies keeping everything in sync — as we've seen, now your views can just watch that source and update themselves on change events. A lot cleaner than if you were storing your data in the DOM. Here's another quote from Backbone's main page:
"When working on a web application that involves a lot of JavaScript, one of the first things you learn is to stop tying your data to the DOM. It's all too easy to create JavaScript applications that end up as tangled piles of jQuery selectors and callbacks, all trying frantically to keep data in sync between the HTML UI, your JavaScript logic, and the database on your server. For rich client-side applications, a more structured approach is often helpful."
Backbone CRUD
Out of the box Backbone provides CRUD functionality for RESTful backends. For this task Backbone's Model and Collection classes provide properties and methods like save() and sync() that make communicating REST requests to a server very straightforward.
For example, you can commit a Backbone model's data to a backend datastore by calling the Backbone Model's save() method on a model instance. This kicks off a sync-to-db process that begins with data validation. While no validation is required, if you do specify a validation routine then Backbone runs it before save() executes. If validation fails then the save won't happen — instead you'll get an invalid event and the event handler you've provided will execute (usually displaying an error message to the user).
If the data passes validation then the model will delegate to the sync() method. Sync() sends model data to a server based on the properties you've set on the model or its containing collection. For example, to a collection's url property you can assign the RESTful endpoint of your back-end data handling process. The server call is made via jQuery's ajax method (or Zepto's or lodash's if you've substituted one of those), to which you can pass parameters. If the model you're saving is a new record then the data is sent with POST; for edits of existing records it's sent with PUT. Serialization is handled by the sync routine, with the data sent in JSON format.
The point here is that you don't have to work out the entire CRUD commit process yourself, Backbone provides a flexible mechanism for this that you can use as-is or build upon. As with so much in Backbone, there's a lot of flexibility throughout the sync-to-db process. For example, if the standard sync() processing doesn't meet your needs you can override it (and you can do this globally, or at the collection level, or even at the individual model level). You might do this to insert your own serialization routine, or if your backend doesn't use a RESTful JSON API, or you might add a persistence layer. JSCT demonstrates overriding the REST-based defaults through its use of localStorage, which is covered in the next section.
While JSCT uses localStorage as its data store, Backbone applications generally use REST to do server-based data operations. For this you define your RESTful endpoint via the url property in your Backbone collection. Models in the collection use this url property to construct the url required for their REST operations. For more on the Collection url property see this entry in the Backbone doc (this Stackoverflow is also useful).
For an overview of Backbone CRUD functionality and its use of REST see the Backbone Wiki Primer.
JSCT demos CRUD functionality in its Detail view (js/views/detail.js). This view allows the user to create, update and delete codeTrack items. This view (in combination with the CodeTrack model) also demonstrates a basic use of Backbone's built-in validation features.
JSCT use of localStorage
JSCT uses localStorage (a.k.a. web storage and HTML5 storage) as its datastore, and a head's up is in order here: using localStorage as your datastore isn't something you'd often do in a real-world application. At least not for your domain data. That's because localStorage data is stored on the client, meaning that its data isn't shareable. To make things worse, localStorage is browser-specific, so any data you store there isn't even accessible to other browsers on the same device. On the other hand, using localStorage simplified creating this demo app and it lets you pull down and play with the code without having to set up a RESTful backend.
| |
JSCT's use of localStorage keeps things simple but does have side effects — because data is stored locally it can't be shared with others. Worse, because localStorage data is browser-specific you even get different data for different browsers on the same machine. |
JSCT uses Jerome Gravel-Niquet's excellent backbone-localstorage adapter. This adapter lets you use Backbone's CRUD methods (i.e., save, fetch, etc.) just as if you were using a RESTful server (one exception: you don't set a url property on Collections, instead you set a localStorage property — see previous section for more on Collection url property). If you want to explore Backbone without setting up a RESTful backend then backbone-localstorage adapter is for you (bonus: dead simple setup).
In JSCT all localStorage reads and writes are handled in JSCT's application controller (js/appController.js). That module isn't part of the application's logical Model layer, but doing data load in application controllers seems fairly common. On the other hand, because JSCT uses localStorage to store domain data its initial data load is non-standard — that's covered in the next section.
In addition to using localStorage to store its coding tips and traps data JSCT also uses it to store application state. This application state data is used to persist sessions — at application initialization the saved state is used to populate the application model and restore previous application state. For info on this see the Application Controller section
JSCT data load
Initial data load is handled by the JSCT application controller as a pre-init task. This includes a one-time sample db creation when JSCT finds no existing data (e.g., when a new user first accesses the application).
First-use load
The first time you access JSCT (also when all JSCT data has been deleted) the application controller creates a sample db. Seed data is stored in a JSON file on the server, with the app controller's createSampleDB() function asynchronously pulling this JSON via a jQuery ajax call. The call's success handler uses Backbone Collection's create() method to:
- populate JSCT CodeTrack models from this JSON
- save each model's data as a new item in the application dataStore
- add each new CodeTrack model instance to the codeTrackCollection
Once the sample data has been successfully loaded into jsct.codeTrackCollection the application initialization routine is called.
Normal load
When JSCT finds data in localStorage it loads that data using Backbone's fetch() method. It's important to note that this use of fetch() for initial data load isn't standard — fetch is generally used to refresh data from a server after your application is already up and running. However, here it's used at startup because JSCT's data isn't remote but instead is stored locally, so there's no network latency or http request cost incurred. Just keep in mind that the preferred method for initial data load (recommended on Backbone's site) is to have the server generate your data into your application's initial HTML file. This can improve startup performance by eliminating a HTTP request. The resources below have a bit more info on this.
Resources: initial data load:
- Backbone doc — http://backbonejs.org/#Model-fetch, http://backbonejs.org/#Collection-fetch, http://backbonejs.org/#FAQ-bootstrap
- Item #3 of http://ozkatz.github.io/avoiding-common-backbonejs-pitfalls.html
- http://fragged.org/backbone-patterns/#bootstrapping_data
- rjzaworski.com post on initializing Backbone applications/
UI: views, DOM manipulation, garbage collection
Reminder: this post provides high-level overviews of selected Backbone features and points you to demonstrations of these features in JSCT. For a deeper dive into a topic use embedded links and the links provided in the Resources sections below.
Backbone views
Views are the building blocks of your UI and in Backbone you create your views by extending Backbone's View class. At core a Backbone view is just a JavaScript object with Backbone's data and behavior added in. When extending Backbone's View class you will add in more data and behavior to suit your current needs.
It's important to note here that in Backbone the term view doesn't just refer to the entire web page, a generalized "everything on the screen" definition. Backbone views are more granular, having whatever scope you need — you can define a view that fills the entire browser pane, of course, but a Backbone view can also represent a portion of the page or even something that isn't currently on the page at all, and it can be comprised of a single checkbox, or a grouping of checkboxes, or a grouping of checkboxes and text input fields and buttons all functioning as a logical unit (similar to a UI component or widget). Since we're creating browser-based applications here these views are ultimately composed of DOM elements — <a> and <ul> and <li>, form elements like <label> and <input> and <button>, containers like <div> and <section> and <header>, etc.
Aaron Hardy has a very useful series of posts on Backbone and his post on Backbone views nicely describes Backbone's concept of a view:
"In the traditional web of requesting a new page for each section of a website, we may consider each page a view. Indeed, it is. In modern apps, it's more common to have a single page and, as the user interacts with the page, portions of the page change. Those dynamic portions could likewise be called views. Within a dynamic portion of the page, there may be a toolbar that affects a list of customers. The toolbar could be considered a view. The list of customers could be another view. Each customer row inside the list of customers may be its own view. The row may contain a toggle button which is yet another view. The point is, in the Backbone world, the term view doesn't necessary mean "a section of your website". It can be, and oftentimes should be, much more granular than that."
The next few sections review some Backbone view basics and, of course, give JSCT examples.
The view's DOM element and el property
Backbone views are always associated with at least one DOM element. A view may use many DOM elements as children but there's always a top-level element, what you might call its root element. For example, a view that displays a list of items might have a root element of <ul> or <ol> and then append to this element any number of <li> children. A Backbone view's job is to manage this element and its children: populate it (e.g., append other DOM elements as children), handle user interactions with it, update it when its underlying data changes, destroy it when its underlying data model is destroyed, etc.
All Backbone views provide a reference to the view's root node in their el property (also through $el, which is simply the jquery-wrapped el). A view's el always points to a specific DOM node — if you create two instances of the same <ul>—based view their el property will point to two different <ul> DOM nodes.
To set a view's el value:
- you can let Backbone create the DOM element and assign it to the el property. This is probably the most common use case. You tell Backbone what you want and when you instantiate the view Backbone will create an instance of that element for you. It then puts a reference to that instance into your view's el property (it also assigns to $el a jQuery-wrapped reference). The created element (and therefore your view) will be off the DOM until you use DOM manipulation to put it on the DOM (e.g., you could use jQuery's append() to attach your view's el to an element already on the DOM).
- specify the element you want to use through the view's tagName attribute. For example, if you specify
tagName:"li"then Backbone will create an <li> element for your el. JSCT example: CodeTrackListItem view - don't specify an element explicitly, in which case Backbone will create a default empty <div> element for your el. JSCT examples: Detail view, GlobalOptions view, Help view
- you can assign an existing DOM element to your view's el property. This element must exist when you instantiate the view. If that el is already on the DOM then your view will be on the DOM as soon as you instantiate it.
To use an existing DOM element for your el:
- in your view definition you can use a selector to assign an existing DOM element to your view's el property (e.g.,
el:"#myButton"). JSCT examples: CommandBar, FilterBar. - when you create a view you can pass in the identifier of an existing element as a constructor parm (e.g.
new FooterView({el:$("#listFooter")})). JSCT examples: Summary view's creation of its StatusBar child view
Note that assigning an el value within your view's class definition tightly couples your view to that DOM node. More on this below.
- in your view definition you can use a selector to assign an existing DOM element to your view's el property (e.g.,
- you can change a view's el value using the setElement() method. This method not only sets the element for the view but also migrates all event listeners from the current node to the new node. Use this judiciously, see "Notes on setting a Backbone view's el" below for more info. JSCT examples: none, JSCT doesn't use setElement().
To have Backbone create the element for your view's el:
When you have Backbone create the DOM node you can specify properties for the node such as id, class, and other attributes as described in the BB doc. For a JSCT example see Summary view or CodeTrackList view.
While your view code can specify an existing element for its el value (e.g., el:"#myButton") this approach does have a drawback — it can introduce a tighter coupling than you may need, limiting flexibility. In some cases this may not be a concern. For example, JSCT has a commandBar view that persists for the life of the application, and it's always positioned at the top of the screen, and it's always visible. Flexibility isn't a priority here so its el value is set to an element already on the DOM
(el:"#commandBar"). However, for maximum flexibility you should strive to keep your views ignorant of "outside" DOM elements. Christopher Coenraets has a nice bit on this in his
"Backbone Lessons learned" post. Here's a snip:
"A better approach is to make sure a View doesn't know about its hosting document. It should not know about (or assume the presence) of other elements in the document. The knowledge of the View should be limited to the elements in its own template. That will make the view reusable in many different contexts. The corollary of this rule is that a View shouldn't attach itself to a DOM element in its render() method. The render() method should be limited to populating its own "detached" el attribute. The code that invokes the View's render() method can then decide what to do with the View's HTML fragment: attach it, append it, etc. The View is therefore more reusable and more versatile."
Rendering and working with views off-DOM
A Backbone view displays something on the screen, and the generation of that content is the responsibility of the view's render() method. All Backbone views start out with a render method but it's just a stub, this default render is a no-op. It's your job to provide a render implementation that creates the DOM elements your view needs. Of course you want to do this efficiently, and one factor here is doing as much as possible when your view isn't actually on the DOM.
What's the advantage to working off-DOM? By rendering views off-DOM you can minimize expensive repaints and reflows that can occur when modifying elements while they're on the DOM. The idea here is to defer putting your view on the DOM until it (and its child views) are fully constructed. This is particularly important when you're building lists. An example of this can be seen in JSCT CodeTrackList view 's handling of its <li> child views. These child views (the list items) are created, rendered, and then appended to their <ul> parent in a loop, one <li>-based view for each item in the dataset. However, only after all of the items have been rendered and appended is any of this put on the DOM. If these appends were done when the parent was on the DOM then every append would result in a repaint/reflow operation. Doing this processing while the parent is off-DOM avoids those operations — you incur the cost of only a single repaint/reflow operation when that parent is put on the DOM.
One trick to working with off-DOM views is selecting their child elements. Simple jQuery selector syntax that only provides the target and no context won't work for off-DOM elements. That's because the default jQuery search context is the root of the DOM tree so it "sees" only elements that are on the DOM:
// simple jQuery syntax that will *NOT* select off-DOM elements
$('#childElement').addClass("highlight");
As you'd expect, Backbone helps you with this, providing a simple selector syntax this.$(selector ) that a view can use to selecting its children. This works even for off-DOM elements and even if the view is itself off-DOM. Here's an example (this refers to the view):
// BB syntax for selecting child elements, works when view isn't on DOM
this.$("#childElement").addClass("highlight");
Of course, if you really want to use jQuery you can use a more specific selector syntax that provides your view as the context for the search:
// find() syntax has context so works for off-DOM elements
this.$el.find('#childElement').addClass("highlight") ;
// or you can supply context to normal jquery selector
$('#childElement',this.$el).addClass("highlight") ;
The way Backbone views handle DOM events (e.g., click, mouseover, keyup, etc.) is another assist for working off the DOM. In Backbone you use a view's events property to define listeners for DOM events, declaring your listeners in a hash that you assign to the events property (see Events section for details). What's important here is that Backbone sets all of these listeners on the view's el. This lets these handlers catch DOM events fired by the view's el or (this is the key) by any of its children. In other words, Backbone uses event delegation, leveraging the fact that DOM events bubble and can be handled by a parent. Using the view's el for event delegation instead of setting these listeners on the event emitters themselves means these listeners are bound correctly even before your view's child elements are on the DOM. In fact, even before they exist. And they'll be valid even if you re-render the view and re-create those child elements. Why? Because that el exists for the life of the view, it's always available, so attaching the event handlers to the el ensures that they're ready and waiting for DOM events to bubble up as soon as your view is created. Before, during, and even after the view's child elements exist. Of course event delegation isn't specific to Backbone, and you should already be using it in your JavaScript applications, but Backbone encourages and facilitates the use of delegation through its events hash. In JSCT the detail view is probably the best example of this. For more info on consuming events in Backbone views see the Events section below.
Here's a relevant quote from Jeremy Ashkenas, the creator of Backbone (from reddit post):
"A big part of the point of Backbone always providing a view's element ("el") for you, is that your events are valid at all times — regardless of whether the view is in the DOM, if the data is ready yet, or if the template is available. It's a more stateless way to declare your mouse and keyboard events, relying less on the required ordering of your rendering."
Notes on setting a Backbone view's el:
- when you use an existing DOM element for your el you can maximize flexibility by specifying that element at runtime via a constructor parameter. Here's an example from JSCT's Summary view:
- sometimes you want to reparent a view, basically changing its el to a different DOM element. When this happens you definitely do not want to simply assign a new value to the view's el property. That's because DOM event listeners specified in your Backbone events hash are delegated to the view's root DOM element (i.e, your view's el). As a result, changing a view's root element by simply assigning a new value to its el property isn't sufficient, you also need to move those delegated event listeners to the DOM element that will serve as your view's new el. To handle this you can use Backbone's setElement() method. It not only sets the view's el property for you but also migrates all DOM event listeners to the new el (you could also mod the el value and then call delegateEvents(), but setElement() is probably the better approach).
- if you use an existing DOM element for your view's el then keep in mind the behavior of the Backbone View's remove() method — it executes a jQuery remove call that doesn't just take the element off the DOM, it destroys it. This isn't a problem if you weren't planning to use that node again, but if you intended to parent something else onto that DOM node, well, too bad, it's gone. One way to handle this might be to have your view override the view's remove() method and in your override execute a jquery empty() instead of a remove(). With empty() your DOM node stays on the DOM but now it's childless, ready for new content. Unfortunately, this approach causes new problems. That's because jQuery empty() doesn't clear event listeners on the element (unlike jQuery remove()). So any DOM event listeners you'd set via the view's event hash are still there, attached to your now-empty DOM node. And if you don't whack those listeners then you could have at least two problems: first, those listeners probably have references to the view you're trying to replace and they''ll prevent its garbage collection, wasting memory, creating a zombie view (if zombie views are new to you don't worry, they're covered below); second, depending on what your view does these lingering listeners can cause nasty bugs since they may still run code on that zombie view. All of this is one more reason why using an existing DOM element for your view's el isn't usually a great idea, generally it's better to have Backbone create an element for you that you can attach to the DOM where you want. On this topic you might want to read this Backbone issues post especially Jeremy Ashkenas' comments.
new jsct.StatusBarView( {el:this.$("#listFooter")} );
Notes on View render() method:
- render methods generally aren't written to accept input parameters. You just want:
- render methods are usually written to return this (a reference to the view). This allows chaining, letting you do things like:
- when render returns a this reference be careful with that return value. If you assign it to a variable outside the scope of the view then it may later cause problems when you want to remove that view (because outstanding references to a view prevent garbage collection). This topic is covered below in View removal and zombies
render: function() { … your code here… }
This simplifies updating the UI — now anything that has a reference to a view can refresh it with a simple viewReference.render() call. If render accepted parms then the caller would need to know more about the view it was calling, increasing dependency/coupling.
$("#primaryPane").html( newPrimaryView.render().el );
View markup and templates
As we've seen, each Backbone view is associated with some HTML content. This might consist of a single element or it might be something more complex such as a form-like layout of elements. In creating this content your view usually uses some HTML markup as input, though you can do whatever you want for this task, including using jQuery to programmatically create and append elements to your el. However, a common approach is for a view's render method to generate the view's content from one or more templates.
Templates contain chunks of markup. This may be raw markup but usually it also contains placeholders where data should be inserted. At runtime data from the view's model can be substituted into these placeholders. The result is view content tailored to your view's data.
By convention a view's markup is generated by its render method into its el; the elements that render() creates are added as children of the view's el. Ultimately a view's content is accessed through its el property. It's the el property that you use in DOM manipulation to put your view on the screen. Often you'll do this by injecting the view's el into a container (i.e., a <div>, <header>, <section>, etc.) using jQuery's html() function. In the example below a view's render is run to populate the view's el and then that el becomes the content of #primaryPane through a jQuery html() call (note that this render returns a reference to the view, a convention for Backbone view render methods).
$("#primaryPane").html(newPrimaryView.render().el) ;
For some views you'll append rather than replace. An example of this is JSCT's list view. CodeTrackList (which is <ul>-based) builds its list from CodeTrackListItem views (<li>-based). It does this by looping over the collection of models, creating a codeTrackListItem instance for each model, then appending each rendered instance to its own <ul> el. Here's code run for each model (in the code this refers to the CodeTrackList view instance):
var codeTrackListItem = new jsct.CodeTrackListItem({model:codeTrack});
this.$el.append(codeTrackListItem.render().el);
The takeaway here is that your view's content is created by running render to populate the view's el, and (unless you've set el to an on-the-DOM element) you then use DOM manipulation on the view's el to put your content on the DOM.
Underscore templates
JSCT uses Underscore's microtemplates, which are always available to Backbone applications because Underscore is a Backbone dependency. However, if you want to use a different template lib such as Handlebars.js or Mustache.js or something else, well, go ahead — Backbone will work with any templating library.
Features and syntax vary between template libs, with some letting you embed JavaScript code in the template, allowing you to include conditionals, loops, etc. that affect how the markup is generated. Underscore is one of these, and below is a JSCT example.
| |
Underscore syntax is used below, but keep in mind that syntax and features vary between templating libs. |
<script type="text/template" id="status-template"> <div class="codeTracks-status"> <b><%= total %></b> <%= total == 1 ? 'item' : 'items' %> <% if (meetsFilter >= 0) { %> (<b><%= meetsFilter %></b> <%= meetsFilter==1?'matches':'match' %> filter) <% } %> <% if (tagged) { %> <a id="clear-tagged">Clear <%= tagged %> <%= tagged==1?'tag':'tags' %> </a> <% } %> </div> </script>
StatusBar template
In Underscore syntax three sets of substitution symbols are used:
- <%= %> wraps a data value to be substituted
- <%- %> as above but substituted value is HTML-escaped
- <% %> wraps code you want to execute
If you look at line 3 in the code above you'll see that it uses 2 pairs of data substitution symbols (highlighted in yellow). Between these symbols are your data placeholders (in red). When render runs it calls the template function and passes it a data object (sample invocation code below). Within this object is a data value named total. In line 3 the value of total will be substituted between those <b> and </b> tags (first pair of yellow highlights). Line 3 also does a JavaScript ternary operation on total's value to determine
whether to print "item" or "items". So, for line 3 if total=9 the markup generated would be: <b>9</b>items
Lines 4 and 6 have an example of JavaScript logic used to control markup generation (cyan highlight). A conditional on meetsFilter determines whether the filter status markup is generated — when no filter is active the meetsFilter value is set to -1, in which case filter status text won't appear on the statusBar.
The snip of code below demonstrates usage. When render generates markup from status-template it passes in a few data values to be substituted into the template. These values are retrieved earlier in render and stored in vars total, tagged, and meetsFilter — total is number of codetrack items in the db, tagged is the number of items currently tagged by the user, and meetsFilter is the number of items that satisfy the current filter criteria.
template: _.template($('#status-template').html()),
render: function() {
:
:
this.$el.html( this.template(
{ total: total,
tagged: tagged,
meetsFilter: meetsFilter }
));
:
:
Code snip from the StatusBar view
So, putting this all together, if the values passed were total=9, tagged=2, meetsFilter=5 then (with a little help from CSS) you could get a result such as:

You may have noticed that the StatusBar template is wrapped in a <script> tag. To keep things simple JSCT uses a shortcut of embedding its templates in index.html. You can do this by wrapping the template content in a <script> tag with the type property set to something other than type="text/javascript" (here it's type="text/template") and assigning an id that's used to access the template content (here it's "#status-template"). However, while this approach has the advantage of simplicity it also makes templates hard to manage and doesn't scale well. More common is to keep templates in individual files. Using individual template files has lots of advantages — for example, individual files are more easily shared and version controlled, can be pulled deferred async, and their separation can simplify testing (for a bit more on this see my SPA Primer section on templates).
Template alternatives
While use of templates to generate view markup is common practice and has a lot of benefits you can use other methods to create your view's child DOM elements. JSCT explores the following alternatives:
- your view might not need a template if it creates its children programmatically. An example of this is CodeTrackList view. Its child <li>'s are Backbone views themselves, created with a constructor call, so the code is roughly:
- similar to above, if your view uses already-existing DOM nodes (for example, markup included in your initial .html file) then it can assign an existing node to its el through a selector (e.g.,
el:"#commandBar"). And if that node and its children are all that your view needs for its UI then you just won't need a template for this view. For a JSCT example of this see the CommandBar and FilterBar views, they both use markup included in index.html. - views can create their markup via string manipulation. For example:
- you can directly embed simple templates into your view, for example:
var codeTrackListItem = new jsct.CodeTrackListItem( {model:codeTrack} );
this.$el.append( codeTrackListItem.render().el ) ;
Since the codeTrackListItem <li>'s are its only children and they're not created via markup the CodeTrackList view just doesn't need a template.
this.$el.html("<div class='detailMsg detailMsgNoFilter'>"
+ "<h1>Selected item does not meet filter criteria</h1>"
+ "<h2>Item title: " + this.model.get('title') + "</h2></div>") ;
While this can be handy for dev/debugging and maybe for displaying simple status messages (JSCT example: Detail view) it's not really useful for anything non-trivial because the string manipulation quickly gets messy and hard to read and manage. And, of course, it mixes markup into your JavaScript, something you generally should avoid (separation of concerns)
template:_.template("<p>Value is:<%= someModelAttribute %></p>"),
As with string manipulation, this can be handy for dev work but it's probably not a great practice for production code
Nesting views
Backbone views are frequently composed of other views (variously referred to as nested views, child views, sub-views). For example, JSCT's Summary view is composed of a CodeTrackList view and a StatusBar view, and the CodeTrackList view is itself is composed of many instances of CodeTrackListItem. Here's the hierarchy in pseudocode:
<div> Summary view
<ul> CodeTrackList view
<li> CodeTrackListItem view
<li> CodeTrackListItem view
<li> CodeTrackListItem view
:
:
<div>StatusBar view
If you look at the Summary view template (code below, from #summary-template in index.html) you'll see that its markup is very simple, just 2 empty <div>'s, #listMain and #listFooter.
<script type="text/template" id="summary-template">
<div id="listMain>
<!-- a CodeTrackList instance is injected into this div element -->
</div>
<div id="listFooter" class=listFooter>
<!-- a StatusBar instance is injected here to serve as a list footer -->
</div>
</script>
Summary view template
Into each of these <div>'s Summary view injects a Backbone view. It populates the first with a CodeTrackList instance (<ul> with id of #codeTracks-list) and the second with a StatusBar instance (<div> with class of .codeTracks-status). You can see this nesting in the screencaps below.

Sample DOM tree for Summary view and children
The screencap below shows these views with colored borders: Summary view's border is black, its 2 child views are a red-bordered CodeTrackList and its sibling cyan-bordered StatusBar, and of course the CodeTrackList instance has many CodeTrackListItem view children, each with an orange border.

Summary view's nesting
To appreciate the benefits of this type of view composition consider it in terms of responsibilities:
- Summary view is only responsible for creating its two child views (the list and list footer) and putting them on the DOM
- the list view (CodeTrackList) is only concerned with building its list of codeTrack items by creating its child views (the <li>'s) and appending them to itself
- each of those list items (instances of CodeTrackListItem view) is responsible only for displaying one codeTrack model's data and responding to clicks on its own "arrow" and "star" buttons
- StatusBar is responsible only for displaying status of the collection
Breaking things up like this can simplify many aspects of application development. Using modular views with a clearly defined and limited responsibility can simplify construction of and subsequent modifications to your application, making it easier to move things around and/or reuse them elsewhere, especially if you keep those views loosely coupled. For example, the StatusBar view is used as a footer to the list, but it could be moved elsewhere because it isn't coupled to that list — if you instead parented StatusBar to the document's <header> section it would function just as well. It's important to note that another significant benefit of this sort of decomposition and loose coupling is that it can dramatically simplify testing.
| |
For more on CodeTrackListItem see the Events section. That section also describes an alternative list architecture that is much more lightweight through its use of event delegation. |
When you nest views the parent view is usually responsible for its children. Those responsibilities can include not just the creation of the child elements but also their removal when they're no longer needed and maybe even ensuring they're removed when the view is itself removed. That last one isn't always required — for example, JSCT's CodeTrackList doesn't need to keep track of child views so it can later remove() them when it is itself removed because CodeTrackList is a persistent view — it's instantiated and rendered once and then reused, never removed. This persistence can simplify your module's design, and it works nicely for this simple JSCT demo app, but in the real world you'll frequently have views that do need to be removed (or re-rendered). And in those cases your views usually need to do child cleanup. At a minimum this means the view needs to keep track of its children so it can run remove() on them. More work, but it's important to address this, because not performing proper cleanup can result in "zombie" views — views off the DOM but unable to be garbage collected, causing memory leaks and sometimes very nasty bugs. That's covered in the next section.
View removal and zombies
An important part of creating browser-based applications is understanding JavaScript garbage collection and the causes of memory leaks. For traditional web pages memory leaks aren't much of a concern because a page's memory is reclaimed when it's replaced by another page. But browser-based applications that may have few page loads (or in the case of SPAs have only a single initial page load) must pay attention to memory use and cleanup. Leaks can affect performance and stability, especially on mobile where memory is limited.
| |
JavaScript applications can have memory leaks caused by objects that can't be garbage collected. While this applies to Backbone applications this issue isn't specific to Backbone, it's true of all js-based applications (and all garbage-collected languages). The good news is that Backbone has features to make memory reclamation a bit easier. |
One cause of memory leaks in Backbone applications is failure to remove a view completely — for example, you call a view's remove() method but after it executes there's still some part of your application holding a reference to that view. In this case a leak can occur because of the nature of JavaScript garbage collection — an object can be gc'd only when your application has no references to it. So, no reference to the view stored in a global var, no reference somewhere in your application controller, no reference held by a parent view, and especially no references within one of your event listeners (more on that in a moment...).
All of this is relevant to Backbone views. While running remove() on a view cleans up view references that Backbone knows about, if some part of your application retains a reference to the view even after remove() has been run then that view will remain in memory. It's your job to ensure this doesn't happen, which you really want to do, because when view references remain after you've run remove() bad things can happen. For one thing, your view will disappear (because remove() takes it off the DOM) but really it's still hanging around, lingering in memory. Views like this are often called zombies — they aren't alive but they aren't quite dead yet, either. And, just as in the movies, zombies cause problems.
Imagine a Backbone view that displays a list, maybe it's a <ul>-based view with <li> children. Now imagine that those list item children are themselves Backbone views, so we have nested views here, with each list item view a child of the list view. Now imagine you're done with that list view and want to dispose of it. Fine, you run remove() on it. But what happens to all of those child views? Well, you don't see them on the screen, but that's because their list view parent is gone, so they have no connection to the DOM. But if you didn't run remove() on those list item views then it's very possible that there are outstanding references to them, frequently it's references held by event listeners they've set on a model or collection. And if your list had a lot or items and/or your list item views were heavyweight then you could be wasting signficant memory, because their memory will stay locked up until something clears whatever references are preventing them from being garbage collected. Do this sort of thing often and you'll have problems.
It gets worse. Because if your view becomes a zombie and there are event listeners pointing to its methods then those listeners are still active. That is, they'll still respond to any events they receive. Which isn't what you expected, since you thought you whacked that view. Depending on what your event handler is doing this can cause some very nasty bugs. Sometimes these bugs are obvious. In an early version of JSCT I set my detail view's el incorrectly, leaving listeners uncleared when I replaced an existing detail view instance with a new one. Because of this whenever I viewed a model in detail view some listeners were set and never cleared. Well, guess what happened when I finally clicked the "Delete" button in a detail view. Yep, not only did the model I was viewing get deleted but when that delete button's click event bubbled up to my view's el those zombie views also responded. The result: in one fell swoop every model I'd viewed in that session was deleted. Yikes. Still, at least this bug was obvious. Sometimes zombie views cause much subtler bugs that can be very hard to find and kill.Bottom line for all of this: you need to be aware of JavaScript memory issues and write your application to ensure that memory can be reclaimed. The remainder of this section will cover aspects of avoiding memory leaks in Backbone applications.
Avoiding and clearing references
As noted above, an object can't be garbage collected when there are active references to it. This means that memory management is one more reason you should avoid having your views maintain direct references to each other. Whenever possible have your views communicate indirectly via events (the publish/subscribe pattern is helpful here, allowing you to avoid those references, and that's covered below in the section on Events). In general it's a good practice to avoid storing references to views when you can, it can make memory problems it a bit less likely.
Keep in mind we're only concerned with references to a view that will stay in scope after you run remove() on the view. There's no problem when a view has a reference to itself (after all, that's this). When you run remove() on the view its references to itself will fall out of scope. No, the problem comes from references stored outside the view and which aren't affected by that remove() call — for example a parent view that has stored a reference to one of its children. Of course, as long as you keep track of those references there's no real problem, since that allows for a simple solution — when it's time to whack that view you can just assign a different value to vars holding a reference to that view (any value will do, including null).
An example of this is within the JSCT router — it has a currentPrimaryView property which holds a reference to the currently displayed primary view. Having this reference allows the router to later run remove() on that view when it's about to be replaced by another primary view. After remove() runs the currentPrimaryView property is updated (i.e., it's assigned a reference to the "new" view). And of course that assignment clears the reference to the "old" view. Since the application has no other references to the "old" view it's now a candidate for garbage collection. Below is a simplified version of this (see the router code and its comments for the full implementation).
replacePrimaryView: function (newPrimaryView) {
if (this.currentPrimaryView) {
console.log("ROUTER: running remove() on previous view") ;
this.currentPrimaryView.remove() ;
}
// always store a reference to the new view to allow later remove()
this.currentPrimaryView = newPrimaryView ;
// now fill primaryPane with view's rendered HTML
$("#primaryPane").html(newPrimaryView.render().el) ;
∶
| |
the JSCT router's removal of views is derived from some code in Derick Bailey's Zombies post. While his approach is external to the router and more flexible I'm handling things in the router because I think it makes it easier for a noob to follow the logic |
One last thing re object references preventing garbage collection — keep in mind that this problem isn't limited to views, it applies to everything in JavaScript, from Backbone collections to plain old JavaScript objects — as long as your program has a reference to something then that thing can't be garbage collected.
Event listeners as the cause of memory leaks
Event listeners are a common source of zombie views since the event's handler is often a view method. Which means the listener holds a reference to the view. As we've seen, when you want to really dispose of a view you need to clear all references to it, and references held by event listeners are no exception — view references held by an event listener can prevent your view from being garbage collected.
In talking about clearing listeners I'll cover non-DOM events (e.g., a Backbone model change event) separately from DOM events (e.g., click, mouseover, keyup) because in Backbone you set these differently. Let's start with non-DOM events.
non-DOM events
A big benefit of Backbone comes from the events its classes fire. For one thing, they allow models and collections to communicate with a view without them actually knowing about that view. And through these events your view can easily stay in sync with its data using a listener as shown below (this code uses jQuery on() though in a moment we'll look at a better way):
this.model.on('change', this.render); // ok approach
In the code above this is a reference to the view and this.model is a reference to the model backing the view. You often see code like this in Backbone applications since executing a render whenever the data changes is a great way to keep your view sync'd with its data. However, now when it comes time to remove that view you need to remember to make a jQuery off() call to clear that listener so its view reference (the this.render) goes away. Backbone provides a simpler approach.
Backbone helps with clearing listeners through its listenTo() and stopListening() methods (version 0.9.9+). Use listenTo() to set listeners for non-DOM events (including events fired by Backbone). Here's the above code modified to use listenTo:
this.listenTo(this.model,'change',this.render); // better approach
The advantage here is that all listeners set through listenTo() can be removed by executing a single call to the view's stopListening() method. And you don't even need an explicit call to stopListening(). That's because the view's remove() method does both a jQuery remove() and a Backbone stopListening(). So if you set your event listeners through Backbone's listenTo() instead of jQuery on() and then later you remove your view with the view's remove() method you're good to go — this will kill all of those listenTo() listeners, allowing the view to be garbage collected (presuming you don't have any other outstanding references to the view).
DOM events
Now let's talk about DOM events (things like click, mouseup, drag, etc.). Listeners for DOM events often point to a method in your view as the event handler. As we've seen, these references must be cleared when you remove the view else it can't be garbage collected. Backbone helps you with this through its View class's events property.
Using a view's events property you can declaratively define listeners for DOM events fired by the view itself (i.e., by its el or by any of its child elements). I won't cover the details of using the events property here, that's covered in the Events section. What's important here where we're talking about avoiding zombies is that Backbone handles all of these DOM events in a way that makes it easy to later remove them. It does this by using event delegation. That is, it sets all DOM event listeners on your view's el, catching and handling events fired by child elements as they bubble. And (here's the key when you're trying to avoid zombie views) setting these listeners on the view's el simplifies later removing them. That's because a view's remove() method whacks the view's el, and that in turn clears all listeners attached to that el. That's it, very simple, just use Backbone's events hash to set your DOM event listeners and use Backbone's remove() to dispose of your view and you won't have to worry about having memory leaks caused by DOM event listeners.
Here's a relevant bit about remove() from Derick Bailey's post "Zombies! RUN! (Managing Page Transitions In Backbone Apps)"
"The call to `this.remove()` delegates to jQuery behind the scenes by calling `$(this.el).remove()`. The effect of this is 2-fold. We get the HTML that is currently populated inside of `this.el` removed from the DOM (and therefore, removed from the visual portion of the application), and we also get all of the DOM element events cleaned up for us. This means that all of the events we have in the `events: { … }` declaration of our view are cleaned up automatically!"
Bottom line when it comes to clearing listeners: if for non-DOM events you use listenTo() to set your listeners and for DOM events you use the view's events property to set your listeners then you can clear all of your listeners with one simple remove() call. If you're not quite clear on how this works then consider jumping ahead to the Events section of this post and reading up on how the Backbone handles events, hopefully that will help.
While Backbone's remove() is helpful keep in mind it's not magic — to avoid memory leaks you always need to ensure you don't still have active references to a view after you've remove()'d it.
Finding and killing zombies
Ok, I've covered what memory leaks are and how to avoid them. The natural questions now are: how can I check to see if I have memory leaks? how can I find the cause of a leak? Sorry, but that's a big topic and beyond the scope of this post. To help you out, though, I've included some useful resources on the task of hunting and killing zombies, some especially focused on Backbone applications development.
Resources: Memory leaks, garbage collection, zombies, debugging
Backbone-related:
- Derick Bailey's Backbone.js And JavaScript Garbage Collection is a little old so it doesn't cover newer Backbone features like listenTo() but it's a good intro to the issue of memory leaks and how js garbage collection works.
- this post from Derick Bailey, Zombies! RUN! (Managing Page Transitions In Backbone Apps), covers how event handlers can cause zombies (but it's also pre-listenTo()), so keep in mind that listenTo() eliminates the need for a close() method as he describes it)
- "Backbone.js - Should nested Views maintain references to each other?" is a useful SO on nested views, including addressing managing references and cleanup
- Backbone issues post #2490 "Providing a bare bones convention for nested views" is a discussion on the management and cleanup of nested views (with comments from Jeremy Ashkenas)
- Andrew Henderson's tutorial on detecting Backbone memory leaks
- paydirtapp.com's blog post "Backbone.js in Practice: Part I - Preventing Memory Leaks"
- Oz Katz has some related bits in his "Avoiding Common Backbone.js Pitfalls"
General on garbage collection and memory leaks including debugging:
- Check out the section on Garbage Collection in the Smashing post "Writing Fast, Memory-Efficient JavaScript
- Google has a series of posts on using Chrome Devtools for memory use analysis, try this for a start: Chrome developer post on JavaScript memory profiling
- Here's another by the prolific Addy Osmani, "Taming The Unicorn: Easing JavaScript Memory Profiling In Chrome DevTools"
- Here is a Google Breakpoint video on garbage collection and memory profiling
- you'll find more resources related to devtools and finding memory leaks in my SPA Primer part 2 — Developer Tools section
JSCT views
This section has info on JSCT's design and implementations related to views. Keep in mind my previous caveat: JSCT isn't a model application, it's just a demo of selected features.
JSCT uses 9 views, all described below, and most shown in the screencap below.
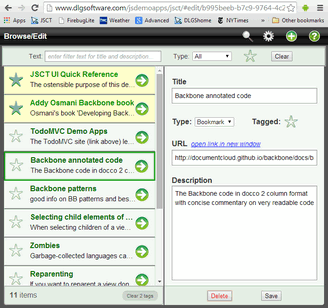
⇦ <header> container "docked" at top of main Flexbox container. Holds views CommandBar and FilterBar. These two views are created at app init and persist for the entire application lifecycle.
⇦ #main content area — holds primary views (definition below). In dualPane layout (shown here) Summary view's list of items is always displayed in the left pane, and user-selected primary view in the right pane. In singlePane layout only the user-selected primary view is displayed.
There are 4 primary views. These are essentially top-level views displayed for a primary application state. For example, the application has a Help state, and when the application is in the Help state the Help view is displayed (mapping of states to views is shown in the table below).
All JSCT primary views:
- are displayed as children of the application's main content area (to be precise, as a child of the <div> #main, which is defined in index.html).
- serve as the UI for an application state (Help view for Help state, Detail view for BrowseEdit state, etc.)
- can be accessed through a URL. For example, the Help state is displayed using the URL dlgsoftware.com/jsdemoapps/jsct/#help This means that application state can be bookmarked and shared via URLs
- are added to the browser's history so the user can navigate to previously displayed primary views using the browser's Back and Forward buttons
- are "remembered" across sessions. That is, at application initialization the last displayed primary view from the previous session is restored. Exception: at app init previous state is not restored when the URL includes parameters — this is required to allow bookmarking (for bookmarking the URL's parms must always "win")
The 4 primary views are:
- Summary (js/views/summary.js) — one view that combines two others (CodeTrackList and StatusBar) into a "big picture" view of the entire collection of codeTrack items. Honors filter criteria.
- Detail (js/views/detail.js) — presents a single codeTrack item. This view does double duty, used for both editing (incl deleting) an existing codeTrack and also used for creating new items. Honors filter criteria.
- Options (js/views/globalOptions.js) — really this is just a placeholder, with one user option to control screen layout and a developer option to enable diagnostics logging to console
- Help (js/views/help.js) — high-level overview of JSCT (mostly it refers you to this post)
JSCT uses application states to drive what's on the screen. When the application state changes so does the primary view. The table below shows the mapping of URL hashpart to application state and the primary view displayed for that state.
|
URL hashpart (route trigger) |
application state value (string stored in application model's currentState attr) |
view displayed |
|
#list |
list |
Summary (list view is a child) |
|
#browseEdit |
browseEdit |
Detail (in browseEdit mode) |
|
#new |
add |
Detail (in addNew mode) |
|
#options |
globalOptions |
GlobalOptions |
|
#help |
help |
Help |
JSCT application states mapping
Three of the non-primary views are child views of the Summary primary view:
- CodeTrackList view (js/views/codeTrackList.js) — a <ul>-based view that creates <li> children for each codeTrack item in the codeTrackCollection and displays these in a list
- CodeTrackListItem (js/views/codeTrackListItem.js) — <li>-based view, displays the data for a single model instance. Has 2 buttons, one for displaying the data in detail view, the other for tagging the item (tagging highlights the item and allows for fast access via filtering)
- StatusBar (js/views/statusBar.js) — used as a list footer, displays status info on the CodeTrackCollection: how many items it contains, how many satisfy the active filter criteria, and a button for resetting all tagged items in the collection to false (i.e., "un-tagging" them)
The remaining 2 views are global views that are children of a <header> container at the top of the screen. Created at app init, they persist throughout the application lifecycle:
- CommandBar (js/views/commandBar.js) — single-line div running along the top of the window. Holds app navigation buttons and global messages. The nav buttons displayed vary based on application state. Buttons are simple anchors with URLs that the application router translates into an application state. Its global messages text can be set by any module via pub/sub.
- FilterBar (js/views/filterBar.js) — lets you apply filter criteria to the data. Its visibility can be toggled using the commandBar magnifying glass button. Hide/show is animated with jQuery, not CSS. In singlePane layout the filterBar is displayed only when Summary view is visible.
Some general notes on JSCT's use of views:
- all are stored under js/views/* and all extend Backbone's View class
- most JSCT views use Underscore templates, although 2 views use markup embedded in index.html (see 4th bullet for details)
- JSCT demos several ways of setting a view's el and its content, including:
-
the view creates its own el, usually by assigning a tag name to its tagName property (e.g.,
tagName: "li"). It creates its child elements through a render() call, usually using templates to generate markup. View is created/destroyed as needed. This is probably the most common use case. Examples: DetailView, GlobalOptions, CodeTrackListItem - view's el is created by its parent and a reference to this element is passed in as a constructor parameter. View creates its own children. Examples: Summary view's creation of StatusBar and CodeTrackList
-
an existing DOM element is used as the view's el (e.g.,
el: "#commandBar) and its content doesn't come from a template but instead is created "externally". Examples: CommandBar and FilterBar use markup embedded in index.html (see next bullet) - While most JSCT views create their UI through templates the CommandBar and FilterBar views show another approach. These two views use existing on-the-DOM <div>'s for their el. More than that, they don't create the DOM elements they need, instead those elements exist and are on the DOM even before the view is created. That's because all elements used by these two views — including their el — are defined in markup within the application load page index.html. In other words, these two views don't create their markup through a render() and a template like most "normal" Backbone views, their markup is wholly external, created and put on the DOM right at application startup. While using existing elements can be useful at times — e.g., for global views like a navbar that you want quickly visible and functional at application startup — keep in mind that it's generally better to have your views as self-contained as possible.
- Most views present data. In Backbone applications that means they’re backed by a Backbone model (usually only one) whose data they display and whose change events they consume. If you pass a model into a view's constructor then a reference to that model will be available in the view as this.model. Examples: both CodeTrackListItem and Detail views display the data of a CodeTrack model instance and in both cases the model is passed in as a constructor parameter.
- while most views display data from a single model they can listen to other models. In JSCT most views set listeners for change events fired by the application model. By listening for application state changes these views can respond to things like browser resize and changes to user preferences (e.g., switching from singlePane layout to dualPane layout).
| |
For more info on these views and the Backbone functionality they demo see the JSCT code — most modules have lots of comments. |
Navigation: routing, use of history, bookmarking
Connecting URLs and application state
Client-driven JavaScript applications often use URLs for navigation. For example, you can display JSCT's online help with:
http://www.dlgsoftware.com/jsdemoapps/jsct/#help
And you can display its options screen with:
http://www.dlgsoftware.com/jsdemoapps/jsct/#options
You can think of these URLs as paths to an application state — one URL may trigger the display of help content, another an options view, another a detail view showing data for a single item, etc. All of this is similar to traditional server-driven web applications — enter a URL and get some content in your browser. However, client-driven applications have one big difference — they use URLs that won't trigger a page load. These URLs will be handled on the client with no page fetch from the server and often with no server interaction at all. This can yield one of the major benefits of client-side js-driven applications — by avoiding the latency and UI disruption of page loads the application can deliver a smoother and faster UI. Eliminating page loads also allows maintaining/persisting application state on the client.
Most JavaScript applications map URLs to application state via a client-side router. Routers translate URL hashparts (or URLs if you use HTML5 history API) into application state through a route map you define (example below). In this route map you register the URL hashpart values you're interested in, mapping each to a router method that you create. Whenever the page's hashpart changes (a change that doesn't trigger a page load) the router checks its route map to see if it includes the new hashpart value. If it does then the router executes the method you mapped to that hashpart value. And of course that method does something to put your application into the new application state (e.g., into the help state for the #help hashpart).
hashpart : method to execute
↓ ↓
routes: { "list": "home",
"help": "showHelp" ,
"edit/:id": "browseEdit" ,
"options": "globalOptions" ,
"*other": "home"
}
Example route map from JSCT router (subset)
For simple applications your route handling methods might directly change application state by creating and destroying views, doing DOM manipulation, setting values on the model, etc. That may be ok for simple applications, and JSCT takes this approach to keep the logic a bit easier to follow. However, for serious applications you probably don't want your router doing this much work. Better to have it delegate the processing that changes application state to a module dedicated to this task, maybe an application controller module. More on this below in the Router's role section.
| |
JSCT uses the URL's hashpart for routing (in URLs above that's the #help and #options). However, Backbone also supports HTML5 history API and pushstate/popstate, which allows you to use "real" URLs (i.e., you don't need to rely on URL hash parts). |
Having URLs that translate into an application state is important for client-driven applications since it provides the benefits that browser users expect — browser bookmarking, returning to previously visited states through the browser's Back and Forward buttons, and sharing application state with others via URLs.
| |
Because JSCT uses localStorage as its datastore you can't share its URLs with others. That's because localStorage data is visible only to the device hosting the browser. If JSCT used a shared backend datastore then users could share URLs. |
Backbone applications implement routing through the Backbone Router and History classes. A Backbone router is where you map URLs to some JavaScript you want to run. For example, the Backbone routes hash shown above maps the #help hashpart to a router method named showHelp. This showHelp method executes JavaScript code that displays the help view.
You can pass URL parameters into your route method. This is demonstrated in the example route map code (see above) by the edit/:id route, which specifies that the route has 1 parameter, :id. With this route the first parm after the URL's #edit hashpart will be passed to the browseEdit method as a parameter. For example, with this URL...
http://www.dlgsoftware.com/jsdemoapps/jsct/#edit/11b66cc9-fc19-92cd-c0f7-c785b2329a93
...the "edit/:id" route will pass the string "11b66cc9-fc19-92cd-c0f7-c785b2329a93" as the value of modelID into the router's browseEdit method shown below:
browseEdit: function(modelID) {
console.log("EXECUTING ROUTE METHOD: browseEdit() w/parm:" + modelID) ;
// do work here to display detail view with data for the selected model
}
Example route handler method with parm
Routes can specify multiple parms, complex parms, optional parms. See the Router section on Backbone's main page for more info on route parms.
It may seem that the Router class handles URL changes and executes the route methods but actually that's the job of Backbone's History class. In fact until you execute Backbone.history.start() your router methods won't execute when the URL changes. That's because Backbone Router delegates most of the real work to the History class to keep things DRY — you might have many router instances but there's always only one History class instantiated (done for you by Backbone, you don't extend and instantiate History like you do Router, it's always already available as Backbone.history).
The History class provides another benefit — it allows users to navigate to previously visited application states via the browser's Back and Forward buttons because it adds the changed URL to the browser's history.
Sometimes it's useful to update the URL programmatically and optionally execute its route. You can do this using the Router navigate() method. For example:
jsct.router.navigate("edit/"+this.model.get('id'),{trigger:true}) ;
A call to navigate() updates the browser's hash part and adds the changed URL to the browser's history. By default that's all it does — any route handler you've defined isn't actually executed. To execute the route handler use the option trigger:true. While using this option is ok in the context of this simple app, be careful with use of the trigger option
It's important to note that we're not talking about representing every possible application state via URLs. Routes generally drive an application's top-level navigation, or primary states — that is, those the user would likely want to bookmark or share via URL (e.g., the online help, options view, detail view for an individual item, etc.)
On the subject of navigation it's worth highlighting a difference between navigating via the browser's Back button versus triggering a route. The difference is in history handling. The route takes you to an application state and also adds that state's URL to the browser's history. Obviously the browser's Back button can also take you to that state if you've previously visited it, but it does so by simply moving "backward" in the browser history. While the end result is the same (display of some application state) these different navigation methods have distinctly different impact on subsequent navigation via the browser's Forward and Back buttons. You can see this by comparing navigation within JSCT using the Back button versus using its Home button (the latter appears at upper left when in singlePane layout and is an anchor whose URL triggers a route that displays the list view and adds to browser history).
Router's role
One last thing: Backbone routers are for routing. However, it's not uncommon to see Backbone applications using the router's initialize method to initialize the application. Some go even farther and make the router serve as an application controller, responding to events other than URL changes. As well, some routers are given the responsibility of changing the application state directly, creating and manipulating your views. Routers with this many responsibilities are often called "god routers". Of course Backbone is incredibly flexible and you can use it as you like, but it's generally better to delegate tasks not directly related to routing to a separate application controller module, keeping the router focused on its real role — translating URL changes to an application state (once again we're talking about the single responsibility principle). On this topic you might want to check out Derick Bailey's post "Reducing Backbone Routers To Nothing More Than Configuration", where he advocates that routers do the absolute minimum, simply catching route changes and then passing on the routing requests to be handled by another module. You might also find useful his comments on this topic at about 37:00 of the JSJabber podcast on Backbone Marionette.
| |
JSCT's router doesn't quite follow the guidelines above — some of its processing really should be pulled out into the appController. However, for this demo app it's been put into the router to make the logic a bit easier to follow. |
Resources:
- Derick Bailey has several of posts on routers — this has a nice intro bit, a good start point: Derick Bailey's post on the responsibilities of the various pieces of backbone
- Aaron Hardy's post on Backbone routers
- http://tech.pro/tutorial/1367/part-1-backbonejs-deconstructed#backbone.router
- If you're new to routing you might find my SPA primer's section on routing useful
Loose Coupling: events and pub/sub
JavaScript applications are event-driven and if you've done any JavaScript programming you've already worked with events. I said at the start I'm assuming you're familiar with both JavaScript and jQuery, so I won't spend time here explaining event-handling basics like event bubbling and how to set event listeners using jQuery's on() function. This section focuses on Backbone's use of events and a related application development topic, the use of an event aggregator to more loosely couple your application modules.
Backbone event handling
As I did in the View removal and Zombies section I'll cover DOM events (e.g., click, mouseover, keyup) separately from non-DOM events (e.g., a Backbone model change event) because in Backbone you handle these differently. Let's start with non-DOM events.
Handling non-DOM events
Backbone classes fire many useful events. To consume these events your thoughts might turn to jQuery's on() function. However, Backbone provides an alternative to on() that can simplify your life when it's time to clear your listeners. This alternative is the listenTo() method, and it's available on all Backbone views (and any other Backbone object that incorporates Backbone events). Its advantage is that all listeners you set via listenTo() can be cleared by a single call to another Backbone method, stopListening(). Because this feature helps with avoiding memory leaks I covered this in the section View removal and Zombies, so refer to that section for info on the usage and advantages of listenTo().
A Backbone view's initialize() method is usually where you set listeners for non-DOM events such as those fired by Backbone models and collections. The code below has an example of this. This code comes from JSCT's CodeTrackListItem view. Each CodeTrackListItem instance is backed by a CodeTrack model instance. In the code below the view sets a listener on its model for change events. Now whenever the model's data changes (say, the user edits that model's data in Detail view) that model's change event will drive a render on the CodeTrackListItem instance displaying its data. That will keep the view in sync with the model data it's displaying. The view also sets a listener for model destroy events. Now if the user deletes a codeTrack item then the model's destroy event will drive the view's removeSelf method, in which the view basically commits suicide, running remove() on itself, which of course results in it being removed from the list, keeping that list in sync with the collection it's presenting.
initialize: function() {
// View listens for changes to its model, rendering on change.
// This keeps it in sync even when model is edited in Detail view
this.listenTo(this.model, 'change', this.render);
// If its model is destroyed then the view destroys itself
this.listenTo(this.model, 'destroy', this.removeSelf);
}
Partial code for CodeTrackListItem view's initialize method
Handling DOM events
DOM event handling is different from the non-DOM event handling described above. For your view's child elements you don't set listeners for DOM events using Backbone's listenTo() or jQuery's on(). Instead you set them declaratively using the Backbone View's events property. This property can be assigned a hash that declares the DOM events you want to handle and their event handler. The simple example below declares click event listeners for 2 anchor child elements (the first has a CSS class of detailButton, the second a CSS class of toggle).
// Each codeTrackListItem (the <li>-based views) contains a "details"
// button (shows the <li>'s data in the Browse/Edit Detail view)
// and a "star" button (lets user toggle the item's "tagged" state)
events: {
"click a.detailButton" : "showDetails" ,
"click a.toggle" : "toggleTagged"
},
CodeTrackListItem view DOM events mapping
While Backbone ultimately does use jQuery's on() to set the listeners that you've declared in the events hash, it does this using event delegation — that is, instead of setting these listeners on the event emitters it sets all of your listeners on their common parent element, the view's el. Delegation takes advantage of the fact that DOM events fired by a child element will bubble up to the element's parents where they can be caught and handled. This use of delegation vastly simplifies setting listeners for the DOM events fired by child elements because you don't need an element to exist in order to define a listener for its DOM events. In other words, because you are setting your listeners on the view's el and that el exists as long as your view exists your listeners can be set even before creating those children via your intial render(). And those listeners will still work if you re-render that view and re-create those children. That's one of the benefits of delegation — because the listeners are attached to your view's el they'll be valid until that el is destroyed or you explicitly remove them with something like off(). Here's a quote from Jeremy Ashkenas on this (source here):
"...the declarative, delegated jQuery events means that you don't have to worry about whether a particular element has been rendered to the DOM yet or not. Usually with jQuery you have to worry about "presence or absence in the DOM" all the time when binding events."
This use of delegation also simplifies your life when it's time to destroy your view. As noted in the View removal and Zombies section, when removing a view you must ensure its listeners are cleared to avoid memory leaks. This is dead simple if you use Backbone's events hash to declare your DOM event listeners because running the view's remove() method whacks the view's el, removing it from the DOM, clearing any data associated with it, and (the one we care about here) clearing any event listeners bound to that el. So, run the view's remove() method and its listeners for DOM events are automatically removed for you.
JSCT's list view (CodeTrackList) uses child views for its <li>'s. Look at the code for CodeTrackList view and you'll see that it creates a CodeTrackListItem view instance for each model (these are the list's <li>'s). Each CodeTrackListItem instance sets listeners on itself for click events, and of course it also sets event listeners on its model for change events. Basically this lets each list item maintain itself, updating its data when necessary, even destroying itself when necessary. It's an attractive design, modular and simple. However, when that list gets large (we're talking thousands of items here) you end up creating a lot of child views and this results in a lot of event listeners. And that can hurt performance. When that happens you should consider an alternate list architecture that makes greater use of event delegation.
A lighterweight solution would be to use "dumb" list items which aren't Backbone views, they'd just be simple <li> nodes with no JavaScript behind them. To handle their click events you'd leverage event delegation, putting your click listeners on a parent element (in our example, CodeTrackList view) and catch those click events as they bubble. With this design you'll have only a few listeners set on a parent element instead of a few set for each <li> view. Of course, now CodeTrackList would need to be rewritten to do more work, not just handling those bubbled events but also updating the child <li>'s when their model changes. More work, but for very large lists this alternate list architecture can translate into better startup performance (not so many listeners to set up) and lower memory use.
Of course, there are other efficient alternatives, such as using the infinite scroll pattern. As always, the optimal design depends on requirements and context.
For a good post that covers some pros and cons of list designs see Derick Bailey's post "Getting the Model ID for a clicked element". Also useful is the "Herding Code" podcast on Backbone at about 46:00.
Some things to note re Backbone event handling:
- in the initialize sample code above a listener was set for CodeTrack model change events:
- for convenience Backbone sets the event handler context (the this value within the event handler) to the view instead of what it would normally be, the dispatching element. This is true for event listeners you set via listenTo() and those set via the view's events hash. This context is generally what you want in a view, and it eliminates the need for a bind() to get the view as your handler's context. Of course, for DOM events the dispatcher is always still available through the event object's target property (also sometimes useful is the jQuery event's originalEvent property).
- because Backbone 's DOM event listeners are attached to your view's el you need to be careful when you want to reparent a view. Never try to change a view's el by simply assigning a new element to the view's el property. That's because of those DOM event listeners — they also need to be moved to the new el. To handle this you can use Backbone's setElement() method. It not only sets the view's el (and $el) value for you but also migrates all DOM event listeners to the new el. Alternatively, you can make use of delegateEvents().
this.listenTo(this.model, 'change', this.render);
That listener will execute when any attribute in the model changes. You can also listen for changes to a specific model attribute. Just use the format change:attribute. For example, the handler in the code below will run only when the application model's filterIsActive attribute changes.
this.listenTo(jsct.application, 'change:filterIsActive', this.setFilterHighlight);
Resources: Events
- Smashing's introduction to DOM events
- Bocoup screencasts on more efficient event handlers
- mattlunn.me.uk blog post on event delegation with jQuery
- Good SO's on listenTo() versus on() here and here
- The Events section of Addy Osmani's excellent Backbone book is helpful
- The Marionette.js post "A deep dive into Backbone.View events" covers how the Backbone view's events hash is processed and how delegateEvents() works
Custom events including Publish/Subscribe
The pub/sub pattern described here isn't specific to Backbone or even JavaScript applications, it's a common application design pattern
Modular applications frequently use events as a way for modules to communicate, with one object setting a listener for another's events. Events help you create modules (or even application layers) that are loosely coupled, minimizing or even eliminating their dependencies on the rest of the application. Of course, having one object listen for another's events doesn't eliminate the dependency created between the two objects, it just gives you control over which module has the dependency.
Consider the case where a module B needs its doSomethingElse() method to execute whenever something happens in a module A. To do this without the use of events module A would need a reference to module B so it can run B.doSomethingElse() whenever module A's "something" happens. This approach makes A responsible for running B's doSomethingElse method. That sets up a dependency where module A needs to "know about" (i.e., have a reference to) module B so it can run B's method. However, through use of events you can flip this dependency, eliminating the need for module A to have a reference to module B. Instead, module A can send out a message (i.e., fire an event) when its "something" happens, and now module B can just listen for this event and respond by running its own doSomethingElse() method (i.e., this method becomes an event handler). Now module B runs its own method. Of course, you haven't eliminated the dependency, you've just reversed it, because to set its event listener module B now needs a reference to module A. Still, this can be incredibly useful — in MVC it's how you can create a reusable model layer with no dependencies on your view layer.
If the above isn't clear maybe this quote from Jeremy Ashkenas will help (source here):
"When first discussing events, it's worth mentioning what they are — a basic inversion of control, where instead of having a function call another function by name, the second function registers its interest in being called whenever the first named "event" happens. The part of the app that has to know how to call the other part of the app has been inverted. This is the core thing that makes it possible for your business logic not to have to "know about" how your user interface works."
While the use of events described above gives you control over which module has the dependency you can take this even farther, eliminating the dependency completely. How? By introducing a middleman. Here we're talking about the Publish/Subscribe pattern.
With pub/sub a central event aggregator serves as middleman for event dispatchers and listeners. Any two objects/components/modules can communicate by having one fire an event through the pub/sub event aggregator (the publish part of Publish/Subscribe) while the other sets its listener for the event on the pub/sub event aggregator (this is the subscribe part). Modules can communicate via events without having references to each other as long as they each have a reference to that middleman.
To implement this you first need an object that can trigger events. How can you fire custom events from a plain old object? Simple, just augment it with something that knows about events. For this you could just use jQuery (any jQuery-wrapped object can fire events) but since we're using Backbone we'll do a mixin of the Backbone events class (first line of code below). BTW, you could just use the Backbone object itself since it can fire events but I like having an object dedicated to this task. Here's the JSCT example:
At JSCT app init an object is enhanced to allow triggering events. This uses Underscore's extend(), which here adds the properties of Backbone.events to the plain object:
jsct.pubsub = _.extend({},Backbone.Events);
Now through this event aggregator any module can "publish" an event, it just needs a reference to the aggregator:
jsct.pubsub.trigger("setMsg","Item doesn't meet filter criteria") ;
And any module with a reference to the aggregator can "subscribe" to pub/sub events:
this.listenTo(jsct.pubsub,'setMsg',this.setGlobalMsg);
JSCT's use of pub/sub allows any of its modules to update the global messageLine without needing a reference to it. And of course fewer references generally translates into fewer dependencies, and fewer dependencies generally translates into code that's easier to write, maintain, and test.
JSCT's pub/sub object is created in the application controller and is available to all objects through an app-global reference jsct.pubsub.
| |
The above is the simplest event aggregator possible, it's just a dumb object except for knowing how to dispatch events. You can have more complex event aggregators that allow you to register callbacks, with the "middleman" responsible for executing the handler function. |
Examples of JSCT pub/sub usage:
- in JSCT the global message line is part of the CommandBar at the top of the screen. It gets its message text via pub/sub. Any module can set the global message by publishing a setmsg event through the pub/sub manager. The CommandBar subscribes to these broadcasts and updates the messageLine based on the event payload. In other words, any module can request that the CommandBar update its messageline, but none of these message-sending modules need a reference to (i.e., dependency on) the message-displaying CommandBar module, nor does it need a reference to those senders in order to receive their message.
- in the GlobalOptions view when the user changes the relative sizes of the left/right panes a splitterLocationChange event is published. The appController module, which is responsible for global layout, subscribes to this event, and responds to it by adjusting the relative widths of the #primaryPane and #secondaryPane divs.
Resources: publish/subscribe (pub/sub) and related decoupling patterns:
- Safari books online article "Decoupling Backbone applications with pubsub"
- MSDN's intro to pub/sub
- Derick Bailey's post on Routing and the event aggregator - coordinating views in Backbone
- Another by Derick Bailey, this about Events aggregator versus Mediators
- my SPA primer's section on events
- Addy Osmani's excellent post on decoupling JavaScript
- Stefanov's "JavaScript Patterns" book, the section on Mediator/Façade
- Osmani's "Learning JavaScript Design Patterns" book available for purchase from O'Reilly or online
JSCT application controller, application model, application state
This section focuses on JSCT design choices more than general Backbone concepts. Reminder: this design is just one possible architecture for a Backbone app, useful for demonstrating selected Backbone functionality, it certainly isn't some Backbone standard.
JSCT uses an application controller module to manage and coordinate application-level tasks. Below is a very brief summary of what application controllers are and what JSCT's does.
Application Controller
Application controllers are modules responsible for app-global tasks during the application lifecycle. This includes things like:
- birth: set up the application environment; initialize the application
- pre-init: execute tasks that need to run ASAP, things like creating your application namespace, bootstrapping the data, loading user preferences, etc.
- init: tasks that need to be run after your core application modules have loaded and the DOM is ready for manipulation. This could include setting up event listeners, creating initial views and adding them to the display, for Backbone applications you might instantiate your Backbone Router and execute Backbone.History.start(), and now that the DOM is ready you'd do app setup DOM manipulation and layout tasks
- life: runtime operations, things like handling global layout issues including adapting layout when the browser is resized (e.g., mobile device change from portrait to landscape), managing top-level views (e.g., flow control for wizard-style applications), possibly serving as an application mediator
- death: perform cleanup tasks and especially save any in-memory data you want to persist across sessions
JSCT uses an application controller module (js/appController.js). Here's a summary of what it does:
- birth:
- pre-init: creates the jsct namespace, verifies that the browser supports localStorage, creates the pub/sub object, loads user preferences, bootstraps data and creates the sample db if there's no existing data in localStorage
- init: reads in and restores previous application state, starts Backbone router and history, creates app-global views (e.g. the commandBar at the top of the screen) and puts those views on the display in the appropriate layout for screen size and user preferences, defines app-global listeners like $(window).resize
- life: manage layout of primary views (e.g., switching between singlePane v. dualPane layouts) including adapting the UI to available screen size, device rotation, and user preferences
- death: save application state to localStorage to allow session persistence
JSCT's application controller has a lot of responsibilities, and normally I'd break it up into more modules or utility functions, but for this demo app I wanted to keep it simple and not decompose things too much (remember that this is targeted to SPA/Backbone noobs). BTW, when reading the application controller code keep in mind that application controllers generally have more dependencies than other modules (i.e., they "know" more about the overall environment).
The next few sections provide some more details on the JSCT lifecycle phases.
| |
JSCT's developer's diagnostics option is a handy way to see what's happening during application load and execution. |
App lifecycle: birth (pre-init and init)
JSCT's pre-init and init phases aren't something defined by Backbone or coming through lifecycle events as you get in many application frameworks. In this simple demo application pre-init equates to: "run as soon as the application controller module is compiled" (it's self-invoking) and init is "run after jQuery document.ready() fires" (in other words, after <script>'s have been compiled and the DOM is ready for manipulation).
As you'd expect, pre-init tasks are mostly focused on establishing/validating the environment needed by JSCT (e.g., checking to see if the browser supports localStorage) and on rate-limiting tasks like data load. For more info on pre-init data load processing see the JSCT Data Load section.
Init tasks focus on getting that initial UI on screen, taking into account any URL parms and user preferences. Note that init restores the previous state, but only if the invoking URL has no hashtag parms — if there are parms then they "win" and the previous session is not restored.
| |
Application state is restored only if the JSCT URL has no hashpart. For more info see "Application model and application persistence" below |
For more info on pre-init and init tasks be sure to see the appController code comments.
App lifecycle: life (runtime)
The main role of JSCT's appController at runtime is to handle layout. Not layouts within individual views, those should always remain the responsibility of the views themselves. Rather, we're talking about layout of your top-level views within the browser viewport, so it's application-level layout, managing the primary app regions like a menubar or commandbar, maybe a utility toolbar or a navigation pane, and of course you always have a container holding your application's main content.
JSCT is written to use 2 main layouts (see table below):
|
singlePane 
|
this layout fills the space below the commandBar with a single container. This container displays the currently active primary view. This layout is forced on for browsers with width LT 700px, otherwise is controlled by user preference. |
|
dualPane 
|
this layout divides the space below the commandBar into 2 side-by-side containers. The container on the left (#secondaryPane) always displays Summary view (the list of codeTracks) . The container on the right (#primaryPane) holds the currently active primary view. Default for browsers with width GE 700px. |
Primary layouts used by the application
JSCT uses these layouts as part of its responsive design — when browser width < 700px the application always uses singlePane layout, while for larger screens the user can use global options to choose whether singlePane or dualPane layout is used.
The best way to explore appController layout changes is to use a desktop browser and resize it. Try this:
- start JSCT in a desktop browser sized so that the application is in dualPane layout, with Summary's list of items in the left pane and the currently active primary view in the right pane
- now start sizing the browser down. The appController method setMainLayout() will respond to browser resize events. It's job is to determine whether the application should be in dualPane or singlePane layout based on browser width and user preferences. When you size the browser width to LT 700px this handler will update the application model's currentLayout attribute, setting it to "singlePane", and this change will trigger execution of updateMainLayout() (see next item)
- appController has a change event listener for changes to the application model's currentLayout property. Whenever the value of currentLayout changes the appController's event handler, updateMainLayout(), does the work of toggling between singlePane and dualPane layouts (described next)
A large part of what happens when toggling between singlePane and dualPane layouts is a reparenting or hiding of Summary view. This is the main job of the appController's updateMainLayout() function, which does DOM manipulation on the #primaryPane and #secondaryPane divs (see DOM hierarchy below) and also sets CSS classes on these divs.

Container hierarchy for dualPane layout
Notes on singlePane/dualPane layout:
- in dualPane layout the pane on the left (#secondaryPane) is where Summary view is parented, while the pane on the right (#primaryPane) displays one of the other primary views (help view, detail view,or options view)
- in singlePane layout #secondaryPane is taken off the DOM and Summary View is displayed in the #primaryPane div just like the other primary views
- in singlePane layout when Summary view isn't on the display it isn't remove()'d, it's just taken off the DOM with jQuery's detach() function, which leaves its data and event listeners intact (unlike jQuery's remove() function)
- CSS classes are also added/removed when switching between singlePane and dualPane layouts
For more on layout via CSS and Flexbox and the use of the #secondaryPane and #primaryPane divs see the Layout section below.
| |
While layout switching is handled by the appController there's also some DOM manipulation for primary views in the router. This is done to make the route handling code easier to follow. However, that view manipulation really should reside in the appController. |
BTW, as you make your browser smaller you won't just see the layout change from dualPane to singlePane, you'll also see subtler changes (e.g., watch the filterbar), mostly adaptations to the narrowing browser width. All of these are done through CSS media queries.
You can force singlePane layout on large screens through a user preference in the global options view.
App lifecycle: death
The controller sets a handler that runs when the user exits the application. For JSCT, "exit" means the firing of the unload or pagehide events. When one of these events fires the appController's saveSession() handler executes, writing the current application state to localStorage. This data can then be used to restore most aspects of the current session when the user next accesses the application. This restoration of application state is covered in the next section.
Application model and application persistence
JSCT is largely driven by application-level state stored in its application model (js/models/application.js).
This client-side application model stores info on selected aspects of the application's state:
- active primary state (domain: "help", "options", "addNew", "browseEdit", "summary")
- active layout (domain: "singlePane", "dualPane")
- status of filter and the filter criteria
- user options/preferences
Note that this model stores only selected aspects of application state — key here is selecting those application properties that are app-global in nature (and, if you want to implement session persistence, that are required to restore state).
Storing aspects of application state in a model simplifies creating views that adapt to application state changes. Views can simply set watchers for state changes and respond to them as required.
For example, JSCT's Detail view displays command buttons along the bottom of the view, but the actual buttons displayed depends on the application's current layout (singlePane v. dualPane). Detail's render() checks the value of the application model's currentLayout property to determine which buttons it should display. Detail view also sets a listener for currentLayout change events so it can update the visibility of those buttons whenever the layout changes.
Another example of a view responding to an application state change is the way the filterBar can be hidden or shown by the user. The commandBar has a button that lets the user hide/show the filterBar (it's the button with the magnifying glass image). When the user clicks on this button the first thing that happens is that CommandBar view updates the showFilterBar property of the application model. Here's the commandBar code that runs when that button is clicked:
jsct.application.set("showFilterBar", !jsct.application.get("showFilterBar"));
CommandBar view response when user clicks hide/show filterBar button
That's all CommandBar view does, it just reverses the Boolean value of the application model's showFilterBar property. Now if the FilterBar view is listening for these showFilterBar change events it can respond by hiding or showing itself based on the changed value of showFilterBar:
this.listenTo(jsct.application,"change:showFilterBar",this.setVisibility);
FilterBar view listens for application state change
This approach allows loose coupling, with the CommandBar view knowing nothing about the FilterBar view (and it certainly isn't directly responsible for setting FilterBar's visibility). The difference between having CommandBar firing the event when the button is clicked versus having it just update a value in the application model and then having that model fire the change event is that storing the value in a model makes this value available for other views to later query — the value persists within the session. And this value can be saved on exit to allow later restoration of the showFilterBar state for the users' next session.
JSCT persists sessions by saving and later restoring application model values across sessions. When the user exits the application most application model values are written to localStorage. When the user next loads the application the initialization process reads the application state stored in localStorage and uses this to populate the application model and thus restore previous application state. Exception: state is not restored when the JSCT is loaded via a URL that has a hash part — when a URL has parameters it's basically specifying a specific application state to be restored, so you always want this bookmarked state to "win". However, use the plain JSCT URL with no hashpart or parms (i.e., www.dlgsoftware.com/jsdemoapps/jsct/) and you'll see most aspects of your previous session restored (e.g., any data filter that was active in previous session).
| |
app state is restored only if the JSCT URL has no hashpart — when a URL has parameters it's basically requesting a specific application state so this bookmarked state has precedence over the saved state |
Use of app-globals
The values stored in the application model are basically app-global values. JSCT also has several app-global references stored in the jsct namespace. Here's a list:
- jsct.pubsub — reference to publish/subscribe utility object
- jsct.router — the application router (only one router is used in this app)
- jsct.application — the application's model; stores some aspects of application state
- jsct.codeTrackCollection — collection holding the codeTrack model instances
- jsct.showDiags — Boolean value that controls writing of diagnostic info to console
- jsct.summary — the lone instance of SummaryView, which persists through entire application lifecycle though sometimes is off-DOM
Resources: application initialization and application controllers
- rjzaworski.com blog post on initializing Backbone applications
- Derick Bailey's post on the 3 stages of a Backbone application's startup
- This next post doesn't directly address application init and application controllers, it's about Derick Bailey's Backbone Marionette, but since Marionette provides a lot of what I've covered above you might find it useful. Even if you don't want to use Marionette you can get some good ideas from it. Smashing's intro to Backbone Marionette
JSCT Layout: CSS, responsive design and Flexbox
JSCT adapts to different screen sizes through some basic responsive design. This is done through straight CSS, not JavaScript, with one exception: for the switch between dualPane and singlePane layouts JavaScript is used to do some DOM manipulation (primarily reparenting of Summary view). This is summarized in the next paragraph.
At initialization JSCT's appController module sets a listener for window.resize events. The resize event's handler deals with browser resizing by choosing the global layout (singlePane or dualPane) to use based on available width and user preferences. Whenever the browser width is LT 700 px (so most phones, at least in portrait) JSCT displays in "singlePane" layout, displaying just one primary view. This is displayed in the div #primaryPane. For larger screens the application defaults to dualPane layout, which uses 2 side-by-side div's with the Summary view always in the left-side pane (#secondaryPane) and the user-selected view in the right pane (#primaryPane).
CSS classes are also added to the divs #primaryPane and #secondaryPane when switching to dualPane layout. These classes set Flexbox properties to make the 2 divs display side-by-side. Flexbox makes it easy to have these 2 child divs adjust to browser resize, proportionally sharing the available space. More on Flexbox below. For more info on JavaScript layout handling see the the description of the appController's updateMainLayout().
Note that using a window.resize listener also handles responding to rotation of mobile devices (better than listening for orientationchange events which have cross-browser issues).
To adapt to different screen sizes JSCT also uses CSS media queries. These are almost all adaptive to width. For example, as the browser gets smaller you'll see some shrinking field widths and hiding of field labels to ensure the line fits without truncation or wrapping. Nothing special here, see the file css/jsct.css.
JSCT also makes heavy use of Flexbox (and, happily, only a single float). Flexbox is a CSS display property supported by modern browsers that simplifies layout, making it easy to size a container to fill all remaining space in its parent container. This is used for layout of the 2 side-by-side divs (#primaryPane and #secondaryPane) — when a width is set on the left pane (default is width:50% but this can be changed through user options view) the right pane will grow/shrink to fill the remaining horizontal space. Flexbox is used like this throughout JSCT, with numerous nested Flexboxes. While a discussion of Flexbox is outside the scope of this doc I do have a Flexbox primer post which includes several Flexbox demos.
| |
While JSCT handles many mobile devices it wasn't optimized for mobile. Its media queries handle down to original iPhone's 320px width ( CSS pixels, that is) but if your phone is below that threshold you'll see layout breakage (for example filterBar will no longer fit on one line) |
JSCT on Mobile
One of my goals with this demo app was to make an application that was not just cross-browser but cross-device, and JSCT uses a single codebase for both modern desktop browsers and mobile browsers. Getting the application to run consistently across modern desktop browsers is relatively easy these days, but consistency across mobile browsers is more of a challenge (when writing cross-mobile it sometimes feels like we're still coding in an IE6 world).
JSCT's handling of differences between mobile and desktop is mostly focused on layout (i.e., responsive design). It does a fair job at this, but on phones you may see layout issues, and on some older phones it's unusable (mostly the problem is the Android 2.3 stock browser which doesn't support scrollable div's). For a list of known problems see the next section.
While JSCT does use responsive design it's otherwise not optimized for mobile (exception: I do load FT's Fastclick, which eliminates mobile browsers' 300ms delay in dispatching click events).
Initial load on mobile can be pretty dreadful because JSCT isn't optimized — for example, it uses many <script> tags, resulting in many HTTP requests at startup. It's important to note that performance issues aren't caused by Backbone, and this application has plenty of potential for performance improvements.
Here are a couple of useful videos on mobile appdev, both from Maximiliano Firtman, an excellent source on the state of mobile browsers and application development.
- "Android and the eternal dying mobile browser"
- "Atmosphere 2014: The mobile web challenges - Maximiliano Firtman"
Known Issues
JSCT is just a demo app, it's not a production app, so I haven't tested exhaustively and certainly haven't tried to test on the dizzying array of mobile devices and browsers now available (note that all issues listed below are for mobile browsers). Moreover, I've simply ignored some small problems (and at least one large one). This section just lists bad stuff I know about.
Also, JSCT doesn't run in some older browsers because I haven't bothered with polyfills or shims. For example, JSCT doesn't run properly in IE9 and earlier because of lack of Flexbox support.
Below are things I either haven't found a workaround for or just haven't bothered to address. Challenge: see if you can detect a pattern here....
- Android 2.x stock: app is unusable because 2.x's stock browser doesn't support div scrolling (i.e., CSS overflow:scroll/auto). Not an OS problem, Firefox on 2.3 scrolls fine. I'm simply ignoring this one (and looking forward to the day when the Android stock browser is finally dead, dead, dead…)
- Android 2.x stock and Firefox on Android 2.x: most anchor buttons are difficult to select, especially the home button
- Android 2.x stock: in portrait difficult to select the "star" button in filterBar — yes, there's close spacing here, but it works fine elsewhere (including Firefox on the same phone). Workaround: switch to landscape.
- Android 4.x stock (some devices): in Detail view when virtual keyboard slides up parts of the screen go black, making it nearly impossible to add a new db item. Slightly less of a problem in portrait mode. Definitely related to the virtual keyboard, when I use my BT keyboard all works fine. Also very possibly related to use of nested Flexbox containers, since this browser uses the older 2009 Flexbox spec
- Android 4.x stock (Samsung-modified): on the original Galaxy Tab 10.1 the URL's hash isn't updating when router.navigate executes. Don't see this problem on newer Galaxy Tabs.
- Android 4.x stock on Samsung devices:
Samsnung-modified stock browser displays a different "filled star" (i.e. ★ ★ CSS entity "\2605") which is not just ugly but largerfixed by substituting a different font just for star chars, see comments in jsct.css - Android 4.x stock: clearing the cache also clears localStorage data. What!!! Yes, the option says "Clear locally cached content and databases" but no other browser uses its "clear the cache" option to clear localStorage, not even Android 2.x stock browser. I mean, it's just utterly brain-dead to clear site local data when clearing the cache, in other browsers that is (and should be) a separate option (usually done via "clear cookies"). What was the dev team thinking!? Again, I look forward to the day when the Android stock browser is dead, dead, dead, dead, dead, dead, dead!!!
- on iPhone the Detail view's description textArea is intermittently disappearing after phone rotation. Seems to happen only after rotation, if you reload page all is fine. Looks to be an iOS 7/8 bug, minor, leaving as-is for now.
- iOS not honoring box-shadow on Save button in Detail view, looks like it's not supported unless you set the button's webkit-appearance:none and that would open a CSS styling Pandora's box, not worth the effort in a demo app so ignoring this one.
- Firefox on Android: Detail view isn't highlighting the Save button correctly because this highlighting is triggered by keyup events from text input fields but in Firefox Android these events aren't getting fired by most keystrokes. Could fix this by listening for input events but that causes problems with Chrome (input fields will highlight upon focus even if you don't edit their text) so will leave this one un-fixed
- iOS Dolphin browser is occasionally clearing localStorage, cause isn't clear, though seems like it might be time-dependent (i.e., expiration). Is the only browser I've found where localStorage gets cleared without some explicit user action.
Conclusion
As I've tried to make clear throughout this post, JSCT demonstrates Backbone basics but isn't intended to show "the Backbone way" of designing web applications. In part that's because there's really no "Backbone way" since Backbone's flexibility makes it suitable for a wide range of applications, and obviously an architecture that's optimal for one set of requirements might be suboptimal for another. This flexibility is one of its Backbone's main attractions, allowing you lots of options for solving your application development challenges.
Backbone's flexibility derives largely from its simplicity and limited scope. Backbone intentionally limits itself to providing the minimal tools and structure you need to create MV* client-side JavaScript applications. That minimalism helps you avoid the "fixed paths" you find in some frameworks where you sometimes feel you're fighting the framework to implement the design you want. It also makes Backbone easier to learn compared to larger and more complex frameworks (Backbone's site promotes this as "less conceptual surface area").
This simplicity and flexibility also makes adapting existing applications to use Backbone a simpler task than adapting existing apps to use most frameworks. Backbone is like jQuery, there's no heavy buy-in, you can use it a little or a lot depending on your current needs, and you can integrate its features into your applications gradually. With frameworks it's usually all or nothing — adapting an application to use a framework like Angular or Ember means signficant revisions to your existing code in order to fit into the framework's more opinionated and prescriptive architecture.
There's a flip side to Backbone's minimalism, however — since it doesn't hold your hand by trying to fill every possible need you don't always have clear options and an obvious path when it's time to make design decisions. If you're new to JavaScript application development you might find yourself at a loss — what are my choices, what are their pros and cons? This is where all-in-one frameworks that provide lots of integrated functionality can have an advantage over Backbone. Frameworks generally have a wide range of well-integrated web appdev features and a prescribed path for the common problems you'll encounter, making many design decisions for you.
On the other hand, while Backbone itself doesn't hold your hand there's lots of help out there. A large community has developed around Backbone and there are many articles and books to guide you. And there are many high-quality open source plugins/mixins that provide most of the functionality you're likely to need for a wide variety of applications — take a look at "starter kits" like Backbone Boilerplate, "framework lite" extensions like Backbone Marionette or Chaplin, layout with backbone.layoutManager, bidirectional binding through backbone.stickit, and many more (to see some options check out Jeremy Ashkenas' Backbone resources and the Backplug.io site).
Another big attraction of Backbone is that it lets you start with a relatively lightweight foundation and then add in just the libs you need, assembling only the features required for your application and no more. This helps you minimize the size of your application. BTW, Backbone's size is another big attraction — minified and gzipped Backbone is only about 7k while it's only hard dependency Underscore is about 6k.
Of course combining disparate libs and plugins can eventually get complicated and it requires that you keep up with a constantly evolving ecosystem of js appdev libs and plugins. Again, this can be problematic for noobs. And when your application gets really large and has a lot of moving parts then even non-noobs may come out ahead by adopting a full-blown framework like Ember or Angular (for a comparison of Libs versus Frameworks see my SPA Primer Part 2).
My ultimate conclusion re Backbone is that it's simply brilliant because it's brilliantly simple. Backbone doesn't handle everything, but what it does provide can save you loads of time and help you establish a solid MV* foundation for your JavaScript applications.
Original version: July 2015
Copyright © Dan Gronell 2015. Licensed under the Creative Commons Attribution-Noncommercial-No Derivative Works 3.0 unported license. 